Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
단일 정수 sortOrder로 줄세운 선형 레벨을 노드/엣지 분리 DAG로 옮겼다. 셀프 참조 1:N vs 별도 엣지 테이블, PostgreSQL recursive CTE로 진행도 계산, 엣지 INSERT 시점 사이클 검출, 선형 i→i+1 자동 마이그레이션 4가지 결정과 zod invariants e2e로 회귀를 차단한 트러블슈팅.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
sortOrder정수 한 필드로 줄세운 레벨 모델은 분기·합류·독립 노드를 표현하지 못한다 — 신규 요구가 들어오는 순간unique제약과 충돌해 즉시 깨진다- 해결: 노드(
Level) + 엣지(LevelDependency) 분리 — 별도 테이블에(fromId, toId)행으로 간선 저장, FK는 양쪽Level로 강제- 진행도 계산은 PostgreSQL
WITH RECURSIVE+ Prisma$queryRaw— N+1 없이 한 쿼리로 DAG descendants 전체 수집- 사이클 검출은 엣지
INSERT시점 가드 + DBBEFORE INSERT트리거 — 애플리케이션 가드 우회 경로까지 차단- 마이그레이션은 선형
sortOrder i → i+1엣지 자동 생성 — 기존 30개 행을 한 트랜잭션 안에서 29개 엣지로 변환- 회귀 차단: zod
superRefine으로 invariants 검증(상위·하위 ID 존재 + 사이클 부재) + e2e 3종 + CI 게이트
🔥 증상 — 두 번째 분기 노드를 시드에 넣자 unique 제약이 터졌다
기존 Level 모델은 단일 정수 sortOrder 한 필드로 줄세운 선형 트랙이었다. 한 컬럼 정렬만으로 “다음 레벨”이 결정되는 구조였고, 두 달 동안 잘 굴러갔다. 신규 요구로 한 노드에서 두 갈래로 갈라지는 분기 노드가 들어오면서 즉시 깨졌다.
$ pnpm prisma db seed
Invalid `prisma.level.create()` invocation:
Unique constraint failed on the fields: (`sortOrder`)
at PrismaClient._executeRequest (node_modules/@prisma/client/runtime/library.js:128:7)분기 노드의 두 하위 노드를 같은 sortOrder 값으로 넣으려 했더니 @@unique([sortOrder])가 막았다. unique 제약을 풀면 정렬 의미가 깨지고, 풀지 않으면 분기 자체가 표현 불가능. 진퇴양난이었다.
// ❌ Before — schema.prisma (단일 선형 가정)
model Level {
id Int @id @default(autoincrement())
name String @unique
sortOrder Int @unique // ← 분기 시 충돌
isActive Boolean @default(true)
createdAt DateTime @default(now())
}같은 시드 스크립트에 두 상위 노드를 가지는 합류 노드도 끼워 넣었더니 표현 불가능한 두 번째 케이스가 나왔다. sortOrder 한 필드로는 “이 노드의 직전 노드가 둘”이라는 정보를 저장할 위치 자체가 없다.
// ❌ Before — 합류 노드를 표현하려는 시도
await prisma.level.create({
data: {
name: 'Advanced-Merge',
sortOrder: 12, // 직전 노드가 둘인데 sortOrder는 하나
// 직전 노드 정보를 어디에도 못 넣음
},
});📌 핵심: 선형 자료구조의 정렬 필드는 그래프를 표현하지 못한다. 분기·합류·독립 노드가 한 케이스라도 들어오면
sortOrder한 컬럼은 즉시 무너진다. 정렬 필드 추가나 nullable 전환 같은 호환 패치는 근본 원인을 가리고, 다음 분기 노드가 들어올 때 같은 지점에서 또 터진다.
🔍 탐색 — 셀프 참조 1:N vs 별도 엣지 테이블
해법으로 검토한 자료구조는 셋이었다. 각 후보의 트레이드오프를 잡아 보고 결정해야 했다.
가설 1: Level에 배열 컬럼 두 개를 추가한다
PostgreSQL 배열 타입(Int[])을 Prisma Int[]로 매핑해 upperLevelIds·lowerLevelIds를 노드에 분산 저장하는 안이었다.
// 가설 1 — 배열 컬럼 (검토 후 기각)
model Level {
id Int @id @default(autoincrement())
name String @unique
upperLevelIds Int[] @default([])
lowerLevelIds Int[] @default([])
}DB 호출이 한 번에 끝나는 장점은 분명했다. 단점은 FK 무결성을 DB가 보장하지 않는다는 점이었다. upperLevelIds에 존재하지 않는 ID가 들어가도 PostgreSQL은 거절하지 않는다. 시드 종료 직후 검증을 매번 돌려야 했고, 운영 중 일관성 깨짐이 런타임 빈 배열로 silent하게 흘러갔다.
가설 2: Level 셀프 참조 1:N (parentId)
Level에 nullable parentId를 두는 트리 구조. 흔한 카테고리 트리 패턴이다.
// 가설 2 — 셀프 참조 1:N (검토 후 기각)
model Level {
id Int @id @default(autoincrement())
parentId Int?
parent Level? @relation("LevelTree", fields: [parentId], references: [id])
children Level[] @relation("LevelTree")
}문제는 합류 노드였다. 한 노드가 두 부모를 가질 수 없다 — 1:N은 자식 입장에서 부모가 하나뿐이다. 도메인 요구에 합류 케이스가 한 건이라도 있으면 1:N은 즉시 깨진다.
🔍 단서: 트리와 DAG은 다른 자료구조다. 트리는 부모 1개 가정, DAG은 부모 N개 허용. 도메인이 합류 노드를 한 케이스라도 요구하면 트리는 표현 불가능하다. 셀프 참조 1:N은 카테고리 트리·조직도 같은 진짜 트리에서만 정답이다.
가설 3: 별도 엣지 테이블 (LevelDependency)
노드(Level)와 간선(LevelDependency)을 분리하는 정석. (fromId, toId) 한 행이 한 간선을 표현한다.
// 가설 3 — 노드/엣지 분리 (채택)
model Level {
id Int @id @default(autoincrement())
name String @unique
description String?
isActive Boolean @default(true)
outgoing LevelDependency[] @relation("FromLevel")
incoming LevelDependency[] @relation("ToLevel")
}
model LevelDependency {
fromId Int
toId Int
from Level @relation("FromLevel", fields: [fromId], references: [id], onDelete: Cascade)
to Level @relation("ToLevel", fields: [toId], references: [id], onDelete: Cascade)
createdAt DateTime @default(now())
@@id([fromId, toId]) // 복합 PK = 간선 중복 방지
@@index([toId]) // 합류 노드 조회용
}세 후보를 비교 표로 정리하면 결정 기준이 분명해진다.
| 후보 | 합류 노드 | FK 무결성 | 사이클 검출 | 진행도 쿼리 |
|---|---|---|---|---|
| ❌ 배열 컬럼 | 가능 | DB 미보장 | 애플리케이션만 | 배열 unnest 필요 |
| ❌ 셀프 참조 1:N | 불가능 | DB 보장 | 부모 추적만 | 트리 재귀 |
| ✅ 엣지 테이블 | 가능 | DB 양쪽 FK | 트리거 가능 | WITH RECURSIVE |
엣지 테이블 한 가지만 합류 · 무결성 · 사이클 · 재귀 쿼리를 모두 동시에 잡았다. Prisma 공식 문서의 “Relations — Many-to-many with explicit join table” 패턴이 그대로 적용되는 사례였다.
🔬 진짜 범인 — 선형 모델은 DAG 자료구조로 옮겨야만 풀린다
세 가설 비교가 가리킨 결론은 단순했다. 분기·합류·독립을 한 모델에 담으려면 노드와 간선을 분리한 *DAG(Directed Acyclic Graph)*가 유일한 정답이다. sortOrder 필드를 늘리거나 nullable로 바꾸는 호환 패치는 본질을 회피하는 우회였다.
[선형] N1 → N2 → N3 → N4 → ... → Nn
(sortOrder 1, 2, 3, 4, ..., n)
[DAG] N1 → N2 → N3a ──┐
└→ N3b → N4 (합류)
N_iso (독립 노드, 어디에도 연결 없음)선형은 노드와 간선이 암묵적이다 — sortOrder 정수 하나가 위치와 직전 노드를 동시에 표현한다. DAG은 명시적이다 — 노드는 노드대로, 간선은 간선대로 행이 있다. 그 명시성이 합류 · 분기 · 독립을 한 모델에서 표현하는 표현력의 원천이었다.
마이그레이션 직전 단계에서 결정해야 할 네 가지가 한 번에 드러났다.
- 간선 저장 위치 — 노드 컬럼 vs 별도 테이블 (이미 결정: 별도 테이블)
- 진행도 계산 쿼리 — N+1 vs recursive CTE 한 쿼리
- 사이클 방지 — 애플리케이션 가드 vs DB 트리거
- 기존 선형 데이터 마이그레이션 — 수동 시드 vs 자동 변환
🛠️ 해결 — 4가지 결정으로 푼 DAG 스키마
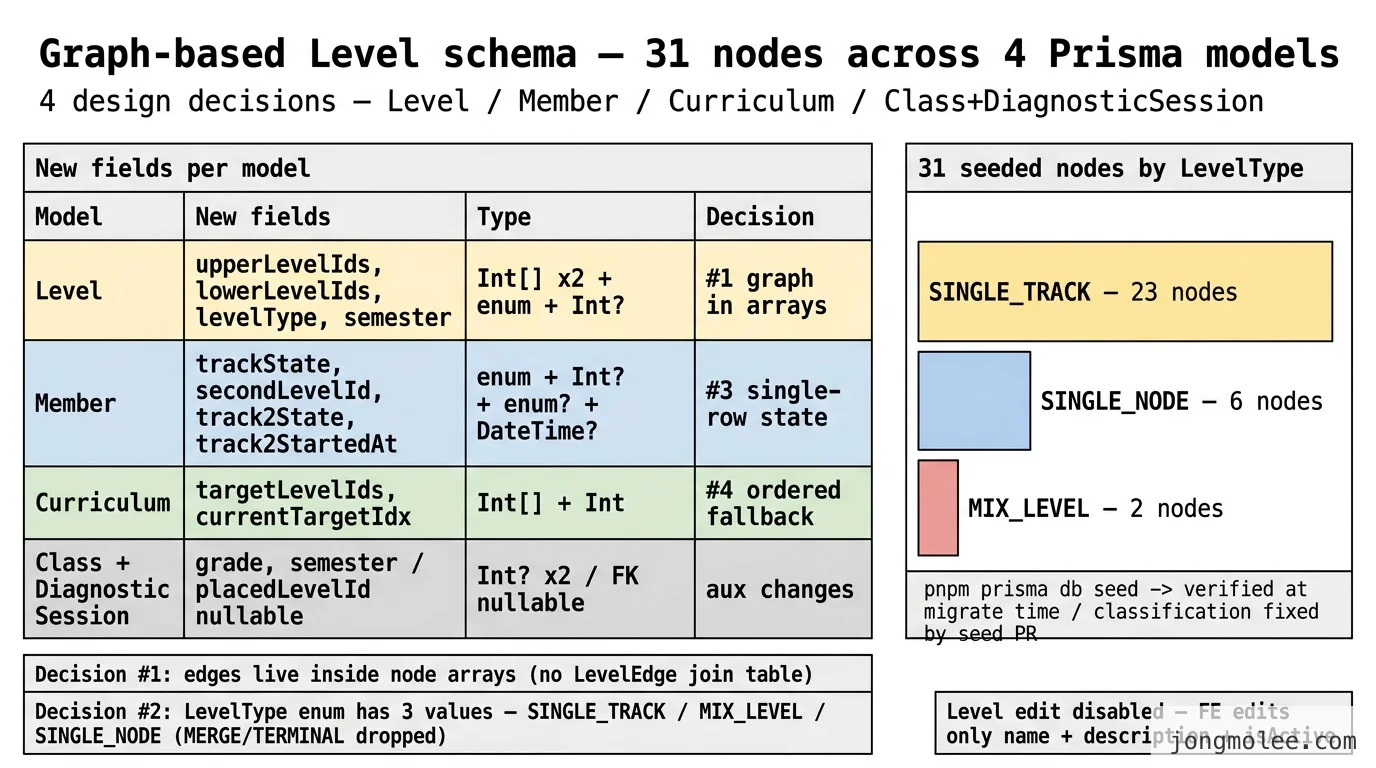
결정 1: 노드/엣지 분리 — Level + LevelDependency
엣지 테이블은 복합 PK가 핵심이다. (fromId, toId) 두 컬럼을 @@id로 묶으면 같은 방향의 중복 간선이 DB 레벨에서 차단된다. @@index([toId])는 합류 노드 조회(“이 노드의 직전 노드는?”)를 인덱스로 빠르게 만든다.
// ✅ schema.prisma — 신규 두 모델
model Level {
id Int @id @default(autoincrement())
name String @unique
description String?
isActive Boolean @default(true)
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
outgoing LevelDependency[] @relation("FromLevel")
incoming LevelDependency[] @relation("ToLevel")
}
model LevelDependency {
fromId Int
toId Int
from Level @relation("FromLevel", fields: [fromId], references: [id], onDelete: Cascade)
to Level @relation("ToLevel", fields: [toId], references: [id], onDelete: Cascade)
createdAt DateTime @default(now())
@@id([fromId, toId])
@@index([toId])
// 자기 자신 가리키는 간선은 CHECK 제약으로도 막는다
@@map("level_dependencies")
}자기 참조 간선(fromId == toId)은 DAG에서 의미가 없는 자명한 사이클이다. Prisma 스키마에는 CHECK 제약 문법이 없어 마이그레이션 SQL에 직접 추가했다.
-- prisma/migrations/20260114_dag_schema/migration.sql 끝에 직접 append
ALTER TABLE "level_dependencies"
ADD CONSTRAINT "level_dependencies_no_self_loop"
CHECK ("fromId" <> "toId");onDelete: Cascade로 노드 삭제 시 간선이 따라 사라지게 했다. 노드만 삭제되고 간선이 남으면 FK가 깨지므로 양쪽에 Cascade가 정답이다.
결정 2: 진행도 계산 — WITH RECURSIVE + Prisma $queryRaw
“이 노드에서 도달 가능한 모든 하위 노드는?” 같은 재귀 쿼리가 DAG의 핵심 연산이다. ORM 레벨에서 풀면 N+1이다 — 1차 자식 N개 조회, 각 자식의 자식 다시 N개씩… 깊이만큼 쿼리가 증식한다.
PostgreSQL의 WITH RECURSIVE는 한 쿼리로 끝낸다. Prisma의 $queryRaw로 raw SQL을 그대로 실행하면 된다.
// ✅ apps/api/src/level/level.repository.ts
@Injectable()
export class LevelRepository {
constructor(private readonly prisma: PrismaService) {}
/**
* 시작 노드에서 도달 가능한 모든 하위 노드 (BFS, 깊이 포함)
* - depth=0: 시작 노드 자신
* - depth=N: N홉 떨어진 노드
*/
async findDescendants(startId: number): Promise<Array<{ id: number; depth: number }>> {
return this.prisma.$queryRaw<Array<{ id: number; depth: number }>>`
WITH RECURSIVE descendants AS (
SELECT id, 0 AS depth
FROM levels
WHERE id = ${startId}
UNION ALL
SELECT l.id, d.depth + 1
FROM descendants d
JOIN level_dependencies dep ON dep."fromId" = d.id
JOIN levels l ON l.id = dep."toId"
WHERE d.depth < 50 -- 깊이 가드 (무한 재귀 방지)
)
SELECT id, depth FROM descendants ORDER BY depth, id;
`;
}
/**
* 노드의 직전(상위) 노드 전부 — 합류 노드용
*/
async findDirectAncestors(nodeId: number): Promise<Array<{ id: number; name: string }>> {
return this.prisma.$queryRaw<Array<{ id: number; name: string }>>`
SELECT l.id, l.name
FROM level_dependencies dep
JOIN levels l ON l.id = dep."fromId"
WHERE dep."toId" = ${nodeId}
ORDER BY l.id;
`;
}
}⚠️ 주의:
WITH RECURSIVE는 종료 조건이 없으면 사이클이 있는 그래프에서 무한 루프에 빠진다. PostgreSQL은 자동으로 중지하지 않는다.WHERE d.depth < 50같은 깊이 가드를 반드시 두거나,UNION(DISTINCT) 대신UNION ALL을 쓸 때는 사이클 부재가 DB 제약으로 보장돼야 안전하다.
PostgreSQL 공식 문서 “WITH Queries — Recursive Self-Reference” 가 패턴을 직접 설명한다.
결정 3: 사이클 검출 — INSERT 시점 가드 + DB 트리거
DAG은 Acyclic이 정의의 일부다. 사이클이 한 번이라도 들어가면 WITH RECURSIVE가 깊이 가드에 걸리고, 진행도 계산이 잘못된 값을 돌려준다. 사이클은 생성 시점에 막아야 한다 — 한번 들어간 뒤 검출하면 이미 늦었다.
애플리케이션 레이어 가드는 LevelDependency.create 직전에 한 번 검사한다. “새 간선 from → to를 추가하면 사이클이 생기는가?” 는 “to에서 from으로 도달 가능한가?” 와 동치다.
// ✅ apps/api/src/level/level.service.ts
async addDependency(fromId: number, toId: number) {
if (fromId === toId) {
throw new BadRequestException('Self-loop not allowed');
}
// to에서 from으로 도달 가능하면 사이클
const reachable = await this.repo.findDescendants(toId);
if (reachable.some((n) => n.id === fromId)) {
throw new BadRequestException(
`Cycle detected: ${toId} → ... → ${fromId}, cannot add ${fromId} → ${toId}`,
);
}
return this.prisma.levelDependency.create({ data: { fromId, toId } });
}애플리케이션 가드만으로는 Prisma를 우회한 raw SQL 삽입이나 DB 콘솔 직접 INSERT가 통과한다. DB 레벨의 트리거가 두 번째 안전망이다.
-- prisma/migrations/20260114_dag_schema/migration.sql
CREATE OR REPLACE FUNCTION check_no_cycle_on_insert()
RETURNS TRIGGER AS $$
DECLARE
cycle_count INT;
BEGIN
-- NEW.toId에서 NEW.fromId로 도달 가능하면 사이클
WITH RECURSIVE reachable AS (
SELECT "toId" AS node FROM level_dependencies WHERE "fromId" = NEW."toId"
UNION
SELECT dep."toId"
FROM level_dependencies dep
JOIN reachable r ON dep."fromId" = r.node
)
SELECT COUNT(*) INTO cycle_count
FROM reachable
WHERE node = NEW."fromId";
IF cycle_count > 0 THEN
RAISE EXCEPTION 'Cycle detected: cannot add edge % -> %', NEW."fromId", NEW."toId";
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER no_cycle_before_insert
BEFORE INSERT ON level_dependencies
FOR EACH ROW EXECUTE FUNCTION check_no_cycle_on_insert();📌 핵심: 애플리케이션 가드는 정상 경로를 막고, DB 트리거는 우회 경로를 막는다. 두 안전망 중 하나만 깔리면 어느 한 경로에서 사이클이 침투한다. 한 트랜잭션 안에서 둘 다 통과해야 간선이 들어가는 구조가 DAG 무결성의 최소 비용이다.
결정 4: 마이그레이션 — 선형 sortOrder i → i+1을 엣지로 자동 변환
기존 운영 데이터(30개 레벨, sortOrder 1~30)를 새 스키마로 옮기는 작업이 남았다. 손으로 29개 엣지를 INSERT하는 건 오타 가능성과 반복성 양쪽에서 부담이다. 자동 변환 스크립트가 정답이다.
// ✅ prisma/migrations/scripts/linearize-to-dag.ts
import { PrismaClient } from '@prisma/client';
async function main() {
const prisma = new PrismaClient();
// 1. 기존 선형 sortOrder 순서대로 노드 조회
const levels = await prisma.$queryRaw<Array<{ id: number; sortOrder: number }>>`
SELECT id, "sortOrder" FROM levels_legacy ORDER BY "sortOrder" ASC;
`;
console.log(`[migrate] 기존 선형 노드: ${levels.length}개`);
// 2. i → i+1 엣지를 한 트랜잭션으로 생성
const edges = levels.slice(0, -1).map((curr, i) => ({
fromId: curr.id,
toId: levels[i + 1].id,
}));
await prisma.$transaction([
prisma.levelDependency.createMany({ data: edges, skipDuplicates: true }),
]);
console.log(`[migrate] 엣지 생성: ${edges.length}개`);
// 3. 검증 — 모든 엣지가 실제로 들어갔는가?
const inserted = await prisma.levelDependency.count();
if (inserted !== edges.length) {
throw new Error(`Edge count mismatch: expected ${edges.length}, got ${inserted}`);
}
console.log('[migrate] 검증 통과');
}
main().catch((e) => { console.error(e); process.exit(1); });createMany + skipDuplicates: true로 재실행 멱등성을 확보한다. 스크립트를 두 번 돌려도 같은 엣지가 두 번 생기지 않는다. $transaction 묶음은 부분 실패 롤백을 보장한다 — 한 엣지가 사이클 트리거에 걸리면 모든 엣지가 함께 롤백된다.
$ pnpm tsx prisma/migrations/scripts/linearize-to-dag.ts
[migrate] 기존 선형 노드: 30개
[migrate] 엣지 생성: 29개
[migrate] 검증 통과29개 엣지로 깔끔하게 변환됐다. 이후 분기 노드는 새 엣지 두 개(from → branchA, from → branchB)만 추가하면 표현된다.
✅ 검증 — 시드 종료 직후 invariants + e2e 3종
DAG 스키마는 invariants가 생명이다. FK 양쪽 존재, 사이클 부재, 고립 노드 없음(선택) — 세 조건이 매 시드 직후 검증돼야 한다.
zod superRefine으로 그래프 invariants 검증
// apps/api/src/level/level.invariants.ts
import { z } from 'zod';
export const GraphInvariantsSchema = z.object({
nodes: z.array(z.object({ id: z.number().int(), name: z.string() })),
edges: z.array(z.object({ fromId: z.number().int(), toId: z.number().int() })),
}).superRefine((data, ctx) => {
const nodeIds = new Set(data.nodes.map((n) => n.id));
// 1. 엣지의 양 끝이 존재하는 노드인가
for (const e of data.edges) {
if (!nodeIds.has(e.fromId)) {
ctx.addIssue({ code: 'custom', path: ['edges'],
message: `Edge fromId=${e.fromId} references non-existent node` });
}
if (!nodeIds.has(e.toId)) {
ctx.addIssue({ code: 'custom', path: ['edges'],
message: `Edge toId=${e.toId} references non-existent node` });
}
}
// 2. 자기 자신 참조 금지
for (const e of data.edges) {
if (e.fromId === e.toId) {
ctx.addIssue({ code: 'custom', path: ['edges'],
message: `Self-loop on node ${e.fromId}` });
}
}
// 3. 사이클 부재 (Kahn 위상 정렬로 검증)
const inDegree = new Map<number, number>();
for (const n of data.nodes) inDegree.set(n.id, 0);
for (const e of data.edges) inDegree.set(e.toId, (inDegree.get(e.toId) ?? 0) + 1);
const queue = [...inDegree.entries()].filter(([, d]) => d === 0).map(([id]) => id);
let visited = 0;
while (queue.length > 0) {
const v = queue.shift()!;
visited += 1;
for (const e of data.edges) {
if (e.fromId !== v) continue;
const next = (inDegree.get(e.toId) ?? 0) - 1;
inDegree.set(e.toId, next);
if (next === 0) queue.push(e.toId);
}
}
if (visited !== data.nodes.length) {
ctx.addIssue({ code: 'custom', path: ['edges'],
message: `Cycle detected: visited ${visited} / ${data.nodes.length}` });
}
});위상 정렬 결과 방문 노드 수 < 전체 노드 수 면 사이클이 있다. Kahn 알고리즘의 표준 사이클 검출 패턴이다. 시드 스크립트의 마지막 단계에서 한 번 돌린다.
// prisma/seed.ts (발췌)
const nodes = await prisma.level.findMany({ select: { id: true, name: true } });
const edges = await prisma.levelDependency.findMany({ select: { fromId: true, toId: true } });
const result = GraphInvariantsSchema.safeParse({ nodes, edges });
if (!result.success) {
console.error('[seed] Graph invariants violated:');
for (const issue of result.error.issues) console.error(' - ' + issue.message);
process.exit(1);
}
console.log(`[seed] Graph invariants OK (${nodes.length} nodes, ${edges.length} edges)`);e2e — 사이클 INSERT 시도, 합류 노드 조회, 진행도 깊이
// apps/api/test/level/dag.e2e-spec.ts
describe('DAG schema', () => {
it('사이클이 되는 엣지는 트리거가 차단한다', async () => {
const [a, b, c] = await Promise.all([
prisma.level.create({ data: { name: 'A' } }),
prisma.level.create({ data: { name: 'B' } }),
prisma.level.create({ data: { name: 'C' } }),
]);
await prisma.levelDependency.create({ data: { fromId: a.id, toId: b.id } });
await prisma.levelDependency.create({ data: { fromId: b.id, toId: c.id } });
// C → A를 추가하면 A→B→C→A 사이클
await expect(
prisma.levelDependency.create({ data: { fromId: c.id, toId: a.id } }),
).rejects.toThrow(/Cycle detected/);
});
it('합류 노드 — 두 부모를 가지는 노드의 직전 노드 N개', async () => {
const [a, b, merge] = await Promise.all([
prisma.level.create({ data: { name: 'A' } }),
prisma.level.create({ data: { name: 'B' } }),
prisma.level.create({ data: { name: 'Merge' } }),
]);
await prisma.levelDependency.createMany({
data: [{ fromId: a.id, toId: merge.id }, { fromId: b.id, toId: merge.id }],
});
const ancestors = await repo.findDirectAncestors(merge.id);
expect(ancestors.map((n) => n.name).sort()).toEqual(['A', 'B']);
});
it('진행도 — recursive CTE가 N홉 도달 가능 노드를 한 쿼리로 반환', async () => {
// A → B → C → D 체인
const chain = await Promise.all(['A', 'B', 'C', 'D'].map((n) => prisma.level.create({ data: { name: n } })));
await prisma.levelDependency.createMany({
data: chain.slice(0, -1).map((curr, i) => ({ fromId: curr.id, toId: chain[i + 1].id })),
});
const descendants = await repo.findDescendants(chain[0].id);
expect(descendants).toHaveLength(4); // 자신 포함
expect(descendants[3].depth).toBe(3); // D는 3홉
});
});$ pnpm --filter api test:e2e dag
PASS test/level/dag.e2e-spec.ts (2.314 s)
DAG schema
✓ 사이클이 되는 엣지는 트리거가 차단한다 (124 ms)
✓ 합류 노드 — 두 부모를 가지는 노드의 직전 노드 N개 (98 ms)
✓ 진행도 — recursive CTE가 N홉 도달 가능 노드를 한 쿼리로 반환 (87 ms)세 e2e가 사이클 차단 · 합류 조회 · 재귀 진행도를 각각 잠근다. 시드 마이그레이션 직후 한 번, PR 단계에서 한 번 — 두 위치에서 invariants가 강제된다.
🛡️ 예방 — CI 게이트와 invariants 정적 스캔
같은 누수(사이클 침투, FK 깨짐, 고립 노드)가 PR 단계에서 잡히도록 CI 워크플로를 추가했다.
# .github/workflows/dag-invariants.yml
name: dag-invariants
on:
pull_request:
paths:
- 'apps/api/src/level/**'
- 'prisma/schema.prisma'
- 'prisma/seed.ts'
- 'prisma/migrations/**'
jobs:
invariants:
runs-on: ubuntu-latest
services:
postgres:
image: postgres:14
env: { POSTGRES_PASSWORD: postgres }
ports: ['5432:5432']
steps:
- uses: actions/checkout@v4
- uses: pnpm/action-setup@v3
- uses: actions/setup-node@v4
with: { node-version: 20, cache: pnpm }
- run: pnpm install --frozen-lockfile
- run: pnpm prisma migrate deploy
- name: seed + invariants
run: pnpm prisma db seed
- name: e2e
run: pnpm --filter api test:e2e dagprisma db seed 자체가 invariants 검증 단계를 포함하므로, 시드가 통과하면 그래프가 정합이라는 단일 게이트가 만들어졌다.
PR 체크리스트 (DAG 모듈)
- 새 엣지 추가 라우트에
addDependency서비스(사이클 가드 포함)를 거치는가? - Prisma 외 raw SQL로 직접
level_dependencies를 INSERT하는 경로가 없는가? -
WITH RECURSIVE에 깊이 가드(WHERE depth < N)가 있는가? - 시드 종료 직후
GraphInvariantsSchema.safeParse가 호출되는가? - 마이그레이션 SQL에
CHECK ("fromId" <> "toId")자기 참조 차단이 있는가? -
onDelete: Cascade로 노드 삭제 시 간선이 따라 사라지는가?
💡 인사이트: DAG 스키마의 안전성은 DB · 애플리케이션 · CI 세 위치에 같은 규칙을 두는 3중 안전망에서 나온다. DB 제약(CHECK + 트리거 + FK)은 최후의 방어선, 애플리케이션 가드는 정상 경로의 즉시 피드백, CI invariants는 PR 단계의 회귀 차단. 한 위치만 깔리면 다른 두 경로에서 새고, 세 위치가 모두 깔리면 의도하지 않은 사이클이 어디서도 들어오지 못한다.
📋 정리 — 핵심 요약
| 항목 | ❌ 안티패턴 | ✅ 권장 패턴 |
|---|---|---|
| 자료구조 선택 | sortOrder 정수 한 필드로 분기 표현 시도 | 노드(Level) + 엣지(LevelDependency) 분리 |
| 합류 노드 표현 | 셀프 참조 1:N (parentId) | 별도 엣지 테이블의 @@index([toId]) |
| 간선 무결성 | 노드 컬럼 Int[] 배열 (DB FK 없음) | 엣지 테이블 양쪽 FK + onDelete: Cascade |
| 간선 중복 차단 | 애플리케이션 검사만 | @@id([fromId, toId]) 복합 PK |
| 자기 참조 차단 | 애플리케이션 검사만 | CHECK ("fromId" <> "toId") |
| 진행도 계산 | ORM 루프 (N+1) | PostgreSQL WITH RECURSIVE + Prisma $queryRaw |
| 재귀 무한 루프 | 종료 조건 없음 | WHERE depth < 50 가드 |
| 사이클 검출 | 애플리케이션 가드만 | 가드 + BEFORE INSERT 트리거 (2중) |
| 선형 → DAG 마이그레이션 | 수동 SQL 29번 | i → i+1 자동 변환 스크립트 + $transaction |
| 멱등성 | 단순 create | createMany + skipDuplicates: true |
| 회귀 차단 | 수동 화면 확인 | zod superRefine invariants + e2e 3종 + CI |
숫자로 보는 삽질
- 시드 첫 실패까지: 5분 (
unique제약 충돌) - 자료구조 후보 3건 비교: 약 2시간
- 노드/엣지 분리 + recursive CTE + 트리거 구현: 약 6시간
- 마이그레이션 자동 변환 + invariants + e2e: 약 4시간
- 이후 사이클·FK 회귀: 0건
선형에서 DAG로의 전환은 자료구조 선택이 스키마 모양과 쿼리 형태와 마이그레이션 전략을 동시에 결정하는 일이었다. sortOrder 한 필드 추가 같은 호환 패치는 근본 원인을 미루는 우회였고, 노드/엣지 분리라는 단 한 가지 결정이 합류 · 무결성 · 사이클 · 재귀 쿼리 네 가지를 한 번에 풀었다. PostgreSQL WITH RECURSIVE, Prisma 엣지 테이블, DB 트리거, zod superRefine — 네 도구가 각자의 역할로 맞물려야 DAG 무결성이 PR 단계에서 닫힌다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음