지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
다섯 개 지표의 점수를 가중평균으로 0~100 범위에 수렴시키던 설계를 폐기하고, 누계 점수를 매 묶음 완료마다 INSERT 전용으로 쌓아 distinct로 최신 1행씩 읽어 TOP1~5 순위를 굳히는 스냅샷 시스템을 짠다. 결정 5건, 트레이드오프, 두 진입점(배치고사 완료·묶음 완료)에서의 호출 패턴, 회복성 try-catch까지 코드 인용으로 정리한다.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- 무엇: 5개 지표(
METRIC_A~METRIC_E) 점수를 묶음 완료마다 누계로 쌓고, 그 누계 기준으로 TOP1~5 순위를 굳히는 운영 시스템- 계산식 변경:
weight × levelMultiplier × accuracy의 가중평균 →weight × (accuracy/100)의 단순 누계 (levelMultiplier삭제, 상한 없음)- 저장 방식 변경: 같은 날 같은 지표 1행
UPDATE→ 매번INSERT전용 (@@unique제거, 이력 자동 보존)- 조회 패턴:
distinct: ['metricCode'] + orderBy createdAt desc로 지표별 최신 1행만 한 쿼리에 모음- 호출 진입점 2곳: 배치고사 완료 시
initializeFromDiagnostic(초기화), 묶음 완료 시updateCumulativeScores(증분) — 둘 다try/catch로 본 흐름과 분리- 백분위 표시 정책:
percentile컬럼 폐기, View단에서score / sum × 100계산 — 표시 정책이 바뀌어도 BE 배포 X
🎯 배경 — 지표 시스템은 사실상 0이었다
이전 편에서 웹 콘텐츠 10종을 같은 PostMessage 봉투로 묶었다. 매 시도마다 16개 통계 필드가 BE로 들어오는 상태가 됐다. 이제 그 데이터를 어디에 어떻게 쌓을지가 남았다.
설계 명세서에서 짚은 현실은 거칠었다.
| 기능 | 명세 |
|---|---|
| 배치고사 지표 저장 | DiagnosticSession.resultMetrics (JSON 한 덩어리) |
| 묶음 완료 시 지표 업데이트 | 미구현 — 호출 자체가 없음 |
지표 순위 조회 (getMemberMetricRanks) | TODO 상태 — 랜덤 순위 반환 |
MemberMetricSnapshot 사용 | 통계 SELECT만, INSERT 호출 0건 |
스냅샷 테이블은 있었다. 호출이 없었을 뿐이다. 거기에 더 큰 설계 문제 두 개가 얹혀 있었다.
첫째, 점수 계산이 가중평균 방식이었다. weight × levelMultiplier × accuracy의 평균을 내고 0100 범위로 잘랐다. 회원이 100문제를 풀든 10,000문제를 풀든 결국 같은 0100 안으로 수렴한다. 학습량이 점수에 누적되지 않으니, 장기 사용 시 TOP1~5 순위 자체가 의미를 잃었다.
둘째, levelMultiplier 라는 임의 설정값이 계산식 가운데 박혀 있었다. 도메인 근거가 약했고 운영자가 조정할 길도 마땅치 않았다. 콘텐츠 가중치(metricWeights)와 정확도(accuracy) 두 신호면 충분했다.
📌 핵심: 지표 시스템의 진짜 결손은 “테이블이 없다”가 아니라 호출이 없다와 수렴하는 계산식이었다. 스키마는 거의 그대로 두고, 계산식과 저장 방식과 호출 진입점만 다시 짜는 작업으로 좁혔다.
이번 작업의 목표는 셋이다.
- 점수는 누계로 쌓되 상한을 두지 않는다 — 학습량이 점수 차이로 남는다.
- 저장은 INSERT 전용 — 이력 자동 보존, 동시성·고유키 충돌 없음.
- 호출 진입점은 두 곳에서 무조건 — 배치고사 완료, 묶음 완료. 실패해도 본 흐름은 막지 않는다.
⚖️ 설계 결정 — 5건과 트레이드오프
명세 검토 단계에서 짚은 결정 다섯 건이다. 각 결정마다 버린 것과 얻은 것을 같이 둔다.
| # | 결정 | 버린 것 | 얻은 것 |
|---|---|---|---|
| 1 | 계산식: 가중평균 → 단순 누계 | 0~100 범위라는 직관적인 표시, levelMultiplier 튜닝 여지 | 학습량 차이가 점수에 누적, 장기 사용 시 순위 의미 유지 |
| 2 | 저장: UPDATE → INSERT 전용 | 행 수 절약, 같은 날 1행 보장 | 이력 자동 보존, @@unique 위반 없음, 동시성 안전 |
| 3 | 조회: 날짜 키 lookup → distinct + orderBy | 단일 행 직접 lookup의 단순함 | 지표별 최신 1행을 한 쿼리에, 이력은 그대로 보존 |
| 4 | percentile DB 저장 폐기 → View단 계산 | DB에 미리 계산해둔 표시값 | 표시 정책 변경 시 BE 배포 불필요, 컬럼 1개 절감 |
| 5 | bundleId 컬럼 추가 (nullable) | 컬럼 1개 부담 | ”어느 묶음이 이 점수를 만들었나” 원인 추적 가능, 배치고사 산 행은 null로 구분 |
결정 1·2가 같이 가는 이유
누계만 도입하고 저장 방식을 UPDATE로 두면 이력이 사라진다. 같은 회원이 같은 지표를 매번 더하면서 한 행만 업데이트하면, “한 달 전 점수가 얼마였나”를 알 길이 없다. 반대로 INSERT 전용만 도입하고 가중평균을 유지하면 행만 잔뜩 쌓이고 점수는 여전히 수렴한다.
두 결정은 한 덩어리로 묶여야 의미가 있다. 누계 + INSERT 전용 + bundleId 추적이 한 세트다.
결정 4가 가능한 이유
백분위는 다섯 지표 사이의 상대값이다. 한 회원 안에서 score / sum × 100만 하면 나온다. DB에 미리 계산해 둘 이유가 없다. 표시 정책(상한 95%, 로그스케일 등)이 바뀔 때 BE를 건드리지 않아도 된다는 점이 결정적이었다.
다만 통계 분석용으로 다른 회원과 비교하는 백분위는 별 얘기다. 그쪽은 다음 편 운영 테이블 도입에서 분리해 다룬다. 이번 작업은 RAW 누계만 책임진다.
🛠️ 구현 — 도메인 서비스 핵심 4 메서드
지표 누계 로직은 MetricAggregationService 한 곳에 모았다. 핵심은 네 메서드다.
1) 콘텐츠 단위 점수 계산 — calculateMetricScore
// metricScore = contentWeight × (accuracy / 100)
calculateMetricScore(
accuracyPct: number,
contentMetricWeights: Record<string, number>,
): Map<MetricCode, number> {
const scores = new Map<MetricCode, number>();
for (const [metricCodeStr, weight] of Object.entries(contentMetricWeights)) {
const metricCode = metricCodeStr as MetricCode;
const score = weight * (accuracyPct / 100);
scores.set(metricCode, score);
}
return scores;
}명세서 초안에는 weight × accuracy로 적혀 있었다. 구현 단계에서 정확도를 0~1 범위로 정규화했다. 가중치(110)와 정확도(0100)를 그대로 곱하면 한 회 점수가 너무 커져, 누계 그래프의 가독성이 떨어졌다.
⚠️ 주의: 콘텐츠 메타의
metricWeights는 난이도별로 다른 가중치를 갖는다 ({ EASY: {...}, NORMAL: {...}, HARD: {...} }). 호출부에서getMetricWeightsForDifficulty(diffWeights, difficulty)로 한 단계 풀어 넘긴다. 이 변환을 도메인 서비스 안에 두지 않은 건 — 난이도 결정은 어플리케이션 레이어(묶음 완료 처리)의 책임이라 판단했기 때문이다.
2) 묶음 완료 시 누계 갱신 — updateCumulativeScores
async updateCumulativeScores(
memberId: string,
bundleId: string,
bundleContents: BundleContentResult[],
): Promise<void> {
// 1. 현재 누계 조회 (지표별 최신)
const currentSnapshots = await this.getLatestSnapshots(memberId);
const currentScores = new Map<MetricCode, number>();
const currentAttemptCounts = new Map<MetricCode, number>();
const currentTotalAccuracy = new Map<MetricCode, number>();
for (const snapshot of currentSnapshots) {
currentScores.set(snapshot.metricCode, snapshot.score);
currentAttemptCounts.set(snapshot.metricCode, snapshot.attemptCount);
// 누적 평균 → 누적 합계 역산 (평균 보존을 위해)
currentTotalAccuracy.set(
snapshot.metricCode,
snapshot.avgAccuracy * snapshot.attemptCount,
);
}
// 2. 이번 묶음의 지표별 점수 합산
const bundleScores = new Map<MetricCode, number>();
for (const content of bundleContents) {
if (!content.metricWeights) continue;
const contentScores = this.calculateMetricScore(
content.accuracyPct,
content.metricWeights,
);
for (const [metric, score] of contentScores) {
bundleScores.set(metric, (bundleScores.get(metric) || 0) + score);
}
}
// 3. 새 누계 계산 및 INSERT (변화가 있는 지표만)
for (const metricCode of Object.values(MetricCode)) {
const previousScore = currentScores.get(metricCode) || 0;
const addedScore = bundleScores.get(metricCode) || 0;
const newScore = previousScore + addedScore;
...
if (addedScore > 0 || previousScore === 0) {
await this.createSnapshot({
memberId, metricCode, score: newScore,
bundleId, attemptCount, avgAccuracy,
});
}
}
// 4. TOP1~5 순위 재계산
await this.updateRanks(memberId);
}네 단계로 끊었다 — 현재 누계 조회 / 묶음 합산 / 새 누계 INSERT / 순위 재계산. 각 단계가 다른 책임이라, 디버깅 로그도 단계별로 찍는다 ([MetricCumulative] UpdateScores → Previous → Added → New → Ranks).
🔍 단서: “변화가 있는 지표만 INSERT” 조건(
addedScore > 0 || previousScore === 0)을 둔 이유는 — 한 묶음 안에 안 풀린 지표는 누계가 바뀌지 않으니 행을 만들 필요가 없기 때문. 단, 점수가 0이고 변화도 없는 신규 회원의 초기 행은 생성해야 해서 두 번째 조건이 붙는다.
3) 배치고사 완료 시 초기화 — initializeFromDiagnostic
async initializeFromDiagnostic(
memberId: string,
diagnosticResults: Record<string, number>, // { METRIC_A: 75, METRIC_B: 80, ... }
): Promise<void> {
for (const [metricCodeStr, accuracy] of Object.entries(diagnosticResults)) {
const metricCode = metricCodeStr as MetricCode;
// 초기 누계 = 배치고사 정확도 × 기본 가중치(10)
const initialScore = accuracy * this.DIAGNOSTIC_INITIAL_WEIGHT;
await this.createSnapshot({
memberId, metricCode, score: initialScore,
bundleId: null, // 배치고사에서 생성된 행
attemptCount: 1,
avgAccuracy: accuracy,
});
}
await this.updateRanks(memberId);
}배치고사 결과는 정확도만 들어온다 (콘텐츠 가중치 개념이 없음). 그래서 기본 가중치 10을 곱해 초기 누계로 쓴다. 이 값은 묶음 완료 한 회의 평균치와 비슷한 크기가 되도록 설계했다 — 초기 점수가 너무 작거나 너무 크면 첫 묶음 완료 직후 순위가 흔들리기 때문.
bundleId: null로 두는 게 핵심이다. 나중에 “이 회원이 배치고사로 받은 초기 점수는 얼마였나”를 WHERE bundleId IS NULL로 한 번에 뽑을 수 있다.
4) 순위 재계산 — updateRanks
async updateRanks(memberId: string): Promise<void> {
const latestSnapshots = await this.getLatestSnapshots(memberId);
if (latestSnapshots.length === 0) return;
// 점수 기준 내림차순 정렬 (높은 점수 = TOP1)
const sorted = [...latestSnapshots].sort((a, b) => b.score - a.score);
const rankOrder: MetricRank[] = [
MetricRank.TOP1, MetricRank.TOP2, MetricRank.TOP3,
MetricRank.TOP4, MetricRank.TOP5,
];
for (let i = 0; i < sorted.length && i < 5; i++) {
await this.prisma.memberMetricSnapshot.update({
where: { id: sorted[i].id },
data: { rank: rankOrder[i] },
});
}
}순위는 최신 행에만 둔다. 과거 행의 rank는 그 시점의 순위를 그대로 보존하고, 새 순위는 새로 들어온 최신 행에 업데이트된다. 이력 조회 시 “이 회원의 TOP1이 한 달 사이에 어떻게 바뀌었나”를 그대로 따라갈 수 있다.
🪜 호출 진입점 — 두 곳, 그리고 try/catch
도메인 서비스가 잘 짜여도 호출이 안 되면 의미가 없다. 진입점은 정확히 두 곳에 둔다.
진입점 1: 배치고사 완료 — MemberDiagnosticApplicationService
// 배치고사 결과 저장 + 레벨 진행 갱신 직후
this.logger.log(
`Diagnostic completed: avgAccuracy=${avgAccuracy.toFixed(1)}%, ...`,
);
// 5. 초기 지표 스냅샷 생성 (신규 도입)
try {
await this.metricAggregationService.initializeFromDiagnostic(
session.memberId,
currentMetrics,
);
} catch (error) {
// 스냅샷 생성 실패해도 배치고사 완료는 유지
this.logger.error(
`Failed to initialize metric snapshots: ${error.message}`,
);
}진입점 2: 묶음 완료 — MemberAssignmentApplicationService.completeBundle
const bundleContentsForMetric = bundle.contents
.filter((c) => c.contentId && c.content?.metricWeights)
.map((c) => {
const difficulty = c.currentAttempt?.difficulty ?? c.difficulty ?? 'EASY';
const diffWeights = c.content?.metricWeights as unknown as DifficultyMetricWeights;
const weights = getMetricWeightsForDifficulty(diffWeights, difficulty);
return {
contentId: c.contentId!.toString(),
accuracyPct: c.currentAttempt?.accuracyPct ?? 0,
metricWeights: weights as unknown as Record<string, number>,
};
});
if (bundleContentsForMetric.length > 0) {
try {
await this.metricAggregationService.updateCumulativeScores(
memberId, bundleId, bundleContentsForMetric,
);
} catch (error) {
// 지표 업데이트 실패해도 묶음 완료는 유지 (try-catch)
this.logger.error(
`Failed to update cumulative scores for bundle ${bundleId}: ${error.message}`,
);
}
}두 진입점 모두 try/catch로 본 흐름과 분리한다. 지표 갱신이 터졌다고 배치고사·묶음의 완료 상태를 되돌리면 사용자 입장에서 데이터가 일관성을 잃는다. 지표는 부수 작업이고, 정합성보다 본 흐름의 회복성이 우선이라는 명시적 결정이다.
📌 핵심: 본 흐름(배치고사 완료 / 묶음 완료) 트랜잭션이 끝난 뒤에 지표 갱신을 부른다. 같은 트랜잭션 안에 묶으면 지표 INSERT 실패가 본 흐름 롤백으로 이어진다. 그건 우리가 원하는 모양이 아니다.
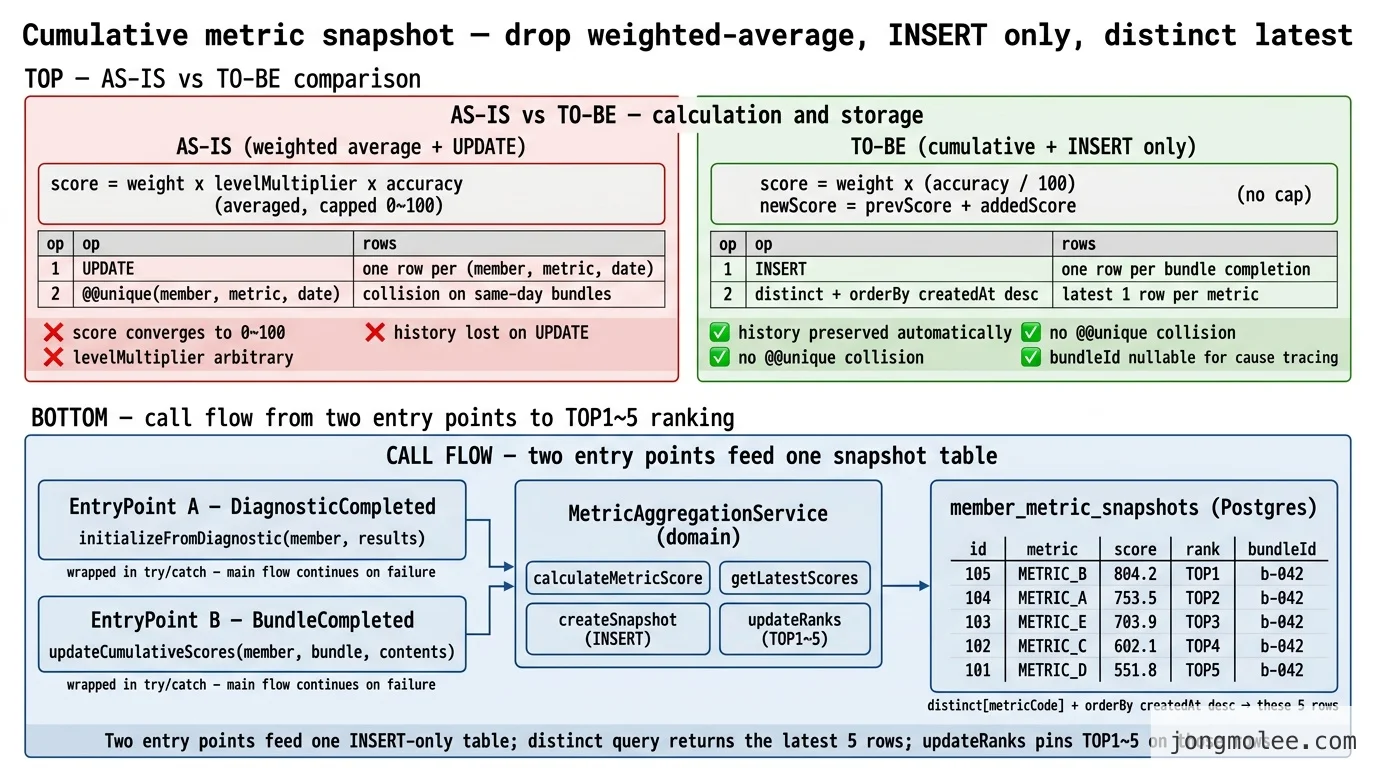
📊 결과 — 어디까지 달라졌나
스키마 변경분 표로 정리한다.
| 필드 | 변경 |
|---|---|
score | 의미 변경: 가중 점수(0~100) → 누계 점수(상한 없음) |
percentile | 삭제 (View단 계산) |
avgTimeMs | 삭제 (사용 안 함) |
snapshotDate | 삭제 (createdAt으로 대체) |
bundleId | 추가 (nullable, 원인 추적) |
@@unique([memberId, metricCode, snapshotDate]) | 삭제 (INSERT 전용) |
@@index([memberId, createdAt(sort: Desc)]) | 추가 (최신 조회용) |
스키마는 컬럼 3개 줄고 1개 늘었고, 인덱스는 unique 1개 빼고 최신 조회용 1개 더했다. 마이그레이션은 한 번에 도는 ALTER 한 묶음으로 끝났다.
호출·로그 패턴
배치고사 한 번 + 묶음 한 번이 한 회원에 들어오면 다음과 같은 로그가 찍힌다 ([MetricCumulative] 태그로 grep 가능).
[MetricCumulative] InitFromDiagnostic - member=u-001
[MetricCumulative] Input: {"METRIC_A":75,"METRIC_B":80,"METRIC_C":60,"METRIC_D":55,"METRIC_E":70}
[MetricCumulative] Created snapshots: 5 metrics, initialScores={...}
[MetricCumulative] UpdateRanks - member=u-001
[MetricCumulative] Ranks: TOP1=METRIC_B(800), TOP2=METRIC_A(750), TOP3=METRIC_E(700), TOP4=METRIC_C(600), TOP5=METRIC_D(550)
[MetricCumulative] UpdateScores - member=u-001, bundle=b-042
[MetricCumulative] Previous: {"METRIC_A":750,"METRIC_B":800,"METRIC_C":600,"METRIC_D":550,"METRIC_E":700}
[MetricCumulative] Added: {"METRIC_A":3.5,"METRIC_B":4.2,"METRIC_C":2.1,"METRIC_D":1.8,"METRIC_E":3.9}
[MetricCumulative] New: {"METRIC_A":753.5,"METRIC_B":804.2,"METRIC_C":602.1,"METRIC_D":551.8,"METRIC_E":703.9}
[MetricCumulative] UpdateRanks - member=u-001
[MetricCumulative] Ranks: TOP1=METRIC_B(804), TOP2=METRIC_A(754), TOP3=METRIC_E(704), TOP4=METRIC_C(602), TOP5=METRIC_D(552)로그 한 묶음을 grep 하나로 줄세울 수 있다는 게 운영 단계에서 결정적이었다. 누계가 0.1점씩만 움직이는 정상 흐름과, 갑자기 100점 점프하는 이상 흐름의 구분이 눈에 바로 들어온다.
숫자로 보는 도입 결과
- 삭제 컬럼: 3개 (
percentile,avgTimeMs,snapshotDate) - 추가 컬럼: 1개 (
bundleId, nullable) - 삭제 메서드: 4개 (
getMetricMultiplier,calculateWeightedScore,calculateTimeWeightedScore,calculatePercentile) - 신규/수정 메서드: 5개 (
calculateMetricScore,getLatestScores,updateCumulativeScores,initializeFromDiagnostic,updateRanks+getMemberMetricRanks실제 구현) - 호출 진입점: 2곳 (
MemberDiagnosticApplicationService,MemberAssignmentApplicationService.completeBundle) — 둘 다try/catch격리 - 로그 태그:
[MetricCumulative]하나로 통일, 5단계(Init/UpdateScores/Previous/Added/New/Ranks) 일관
🔄 회고 — 다음에 같은 결정을 한다면
이번 작업이 끝난 직후 명확해진 한계 두 가지가 있다.
1) 화면 표시 점수와 RAW 누계는 다른 테이블에 넣었어야 했다
누계 점수는 상한이 없다. 좋은 점이지만, 학부모·외부 뷰어에게 “당신 자녀의 METRIC_A 점수는 837.2”를 보여줄 수는 없다. 결국 View단에서 score / sum × 100으로 백분위를 계산하는 패턴을 강요하게 됐고, 화면마다 같은 변환 코드가 반복됐다.
다음 호흡에서 **운영 테이블(member_metric_display)**을 따로 만들었다. RAW는 그대로 두고, 표시용 0~9500 스케일에 로그스케일을 곱해 굳히는 분리 설계로 갔다. 이번 글의 1차 버전은 운영 테이블 분리가 빠져 있다 — 이건 다음 편의 주제다.
2) 동시 묶음 완료에서 순위 재계산이 race 가능
updateCumulativeScores 끝에서 updateRanks를 부른다. 한 회원이 짧은 간격으로 두 묶음을 연달아 완료하면, 두 호출이 같은 회원의 rank 컬럼을 동시 업데이트할 수 있다. 현재는 묶음 완료 자체가 한 회원에 거의 동시에 일어날 일이 적어 우선순위에서 뺐다.
실서비스에서 race가 보이면 — 회원 단위 advisory lock(pg_advisory_xact_lock(hashtext(memberId)))을 묶음 완료 트랜잭션 안에 두는 게 다음 카드다. Prisma는 raw SQL로 advisory lock을 거는 패턴이 있고, 이미 다른 서비스에서 같은 패턴을 한 번 깐 적이 있어 비용이 낮다.
💡 인사이트: 1인 개발 환경에서 결정은 항상 “지금 막을 필요가 있는가”와 “막는 비용은 얼만가”의 곱이다. race는 막을 비용은 낮지만, 지금 막을 필요는 낮다 — 그래서 코멘트로 남기고 다음으로 넘긴다.
🛡️ 예방 — 같은 패턴을 다른 도메인에 옮길 때 체크리스트
이 패턴(누계 + INSERT 전용 + 최신 distinct + 순위 박제)을 다른 도메인에 적용할 때 빠지기 쉬운 함정을 모았다.
- 계산식 정규화 단위 확정 —
weight × accuracy인지weight × (accuracy/100)인지 첫 호출 직전에 고정. 도중에 바꾸면 누계 그래프 단위가 깨진다. - 호출 진입점 try/catch 분리 — 부수 갱신이 본 흐름 트랜잭션 안에 들어가 있지 않은지 한 번 더 확인.
-
@@unique제거 +@@index([entityId, createdAt(sort: Desc)])추가 — 두 변경은 한 마이그레이션에 묶는다. -
distinct + orderBy조합 —distinct만 두면 어느 행이 뽑힐지 보장이 없다.orderBy createdAt desc필수. - 원인 추적용 nullable FK 추가 — 초기화 행(null)과 증분 행(값 있음)이 한 테이블에 섞이는 설계라면 컬럼 1개로 구분 가능.
- 로그 태그 통일 —
[XxxCumulative]같은 prefix 한 개로 묶음 → 운영 grep 한 줄로 모든 단계 추적 가능. - 순위 박제 정책 — “과거 행의 rank는 그 시점 그대로”를 명문화. 잘못 바꾸면 이력 분석이 무너진다.
- View단 계산 폴백 —
sum === 0일 때 0 반환. 신규 회원의 첫 화면이 NaN으로 깨지는 사례를 자주 본다.
📋 정리 — 핵심 요약
| 항목 | AS-IS | TO-BE |
|---|---|---|
| 계산식 | weight × levelMultiplier × accuracy 가중평균 → 0~100 수렴 | weight × (accuracy/100) 단순 누계 → 상한 없음 |
| 저장 방식 | 같은 날 1행 UPDATE (@@unique) | 매번 INSERT 전용 (@@unique 제거) |
| 조회 패턴 | where snapshotDate = ... 단일 행 lookup | distinct ['metricCode'] + orderBy createdAt desc |
| 백분위 컬럼 | DB에 미리 계산해 저장 | 삭제 — View단에서 score / sum × 100 |
| 원인 추적 | 없음 | bundleId nullable 컬럼 추가 (초기화 행은 null) |
| 호출 진입점 | 없음 (TODO) | 2곳 — 배치고사 완료, 묶음 완료. 둘 다 try/catch 분리 |
| 순위 계산 | TODO — 랜덤 반환 | 최신 행에 rank 박제, 과거 행은 그 시점 순위 보존 |
| 로그 태그 | 없음 | [MetricCumulative] 통일 — Init/UpdateScores/Previous/Added/New/Ranks 5단계 |
| 마이그레이션 | — | unique 삭제 + 컬럼 3 삭제 + bundleId 추가 + 인덱스 1 추가 (ALTER 한 묶음) |
| 회복성 | — | 지표 갱신 실패해도 본 흐름은 commit, 에러 로깅만 |
이전 편이 매 시도마다 16개 통계 필드를 BE로 들여보내는 길을 열었다면, 이번 편은 그 데이터를 회원 단위로 누계해 TOP1~5 순위로 굳히는 운영 시스템을 짠 작업이다. 통합 → 누계 → 표시의 세 호흡 중 두 번째다.
다음 편은 이번 글의 회고 1번에서 미뤘던 운영 테이블 분리 — 0~9500 스케일 + 로그스케일 + 95% 하드캡으로 표시 점수를 굳히는 member_metric_display 도입 — 이 아니라, 그보다 먼저 잡혀 있던 배치 작업 첫 구현 — 킥오프 배치와 Winston 로깅이다. 매일 자정 도는 첫 크론 작업에서 만난 멱등성 함정과 로깅 라이브러리 전환 결정을 트러블슈팅 톤으로 정리한다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음