BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
전체 테이블 CUID String PK에서 Mixed ID Strategy(User=CUID, Master=Int, Transaction=BigInt)로 전환한 과정. BigInt JSON 직렬화 버그를 만나고, Junction Table을 다시 Int로 다운그레이드한 첫 번째 스키마 리팩토링 기록.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- 전체 CUID PK를 Mixed ID 전략으로 전환: User 테이블만 CUID 유지, 나머지는 Int/BigInt autoincrement
- PK 타입 선택 기준: 연간 예상 레코드 수 — 10만 건 미만이면 Int, 이상이면 BigInt
- BigInt JSON 직렬화 버그:
JSON.stringify()가 BigInt를 처리 못 해서 API 응답이 깨짐- Junction Table 3개를 BigInt → Int로 다운그레이드: 메타데이터 성격의 테이블에 BigInt는 과잉
- seed 데이터 272건 투입: Level 31개 + ContentItem 19개 + Mapping 158개 + MetricTag 95개
- 교훈: PK 전략은 설계 초기에 확정하되, 실제 데이터를 넣어보기 전까지는 확신하지 말 것
🏗️ 왜 PK 전략을 바꿨나
이전 편에서 27개 테이블을 전부 String @id @default(cuid())로 만들었다. 멀티테넌시 안전성, URL 노출 방지, 마이그레이션 유연성. 합리적인 이유였고, 그때는 그게 최선이라고 생각했다.
그런데 seed 데이터를 넣기 시작하면서 생각이 바뀌었다.
Level 테이블에 31개 레벨을 넣고, ContentItem에 19개 콘텐츠를 넣고, 그 사이의 매핑 테이블(ContentPlayableLevel)에 158건을 넣으려고 보니 — 이 테이블들의 PK가 cksj3k2l10000abcd1234efgh 같은 25자리 문자열이다.
// seed에서 Level → ContentPlayableLevel 연결할 때
const level = createdLevels.find(l => l.name === 'L1');
await prisma.contentPlayableLevel.create({
data: {
contentId: content.id, // "cksj3k2l10000abcd1234efgh" ← ???
levelId: level.id, // "ckrm8x9z20001qwer5678tyui" ← ???
}
});FK로 참조할 때마다 25자리 문자열을 들고 다녀야 한다. Level은 31개밖에 안 되는데 CUID가 필요한가? Academy도 실서비스에서 수백 개를 넘기 어려운데?
📌 핵심: CUID는 분산 시스템에서 충돌 없는 ID 생성이 필요할 때 쓰는 거다. 마스터 데이터처럼 하나의 DB에서 순차 생성하는 테이블에는
autoincrementInteger가 더 효율적이다.
이 깨달음이 PK 전략 전면 재설계의 시작이었다.
🔄 커밋 #11: 대변환 — Mixed ID Strategy
12월 3일 오후 2시 55분. 스키마 버전을 2.0에서 2.1로 올렸다.
// Version: 2.1 (Mixed ID Strategy: User=CUID, Others=Int/BigInt)핵심 아이디어는 간단했다. 테이블의 성격에 따라 PK 타입을 3가지로 나눈다.
전략 1: 사용자 테이블 → String CUID 유지
model User {
id String @id @default(cuid())
// ...
}
model Admin {
id String @id @default(cuid())
// ...
}User, Admin, AcademyOwner, Teacher, Student — 사람을 나타내는 테이블은 CUID를 유지했다. 이유는 원래 CUID를 선택한 이유 그대로:
- URL에 노출될 수 있다 (
/api/students/cksj3k2l1...vs/api/students/42) - 순차 ID로 다른 사용자의 존재를 유추할 수 있다
- 향후 DB 분리/통합 시 충돌 없어야 한다
전략 2: 마스터 데이터 → Int autoincrement
// ❌ Before (v2.0)
model Academy {
id String @id @default(cuid())
// ...
}
// ✅ After (v2.1)
model Academy {
id Int @id @default(autoincrement())
// ...
}Academy, Class, Level, ContentItem, ContentMetricTag, DiagnosticVersion — 이런 마스터 데이터 테이블은 Int로 바꿨다.
공통점이 있다:
- 레코드 수가 많지 않다 (Level은 31개, Academy는 수백 개 수준)
- 다른 테이블에서 FK로 자주 참조된다
- URL에 직접 노출되지 않는다 (관리자 API에서만 사용)
Int의 범위가 약 21억(2,147,483,647)이다. Level이 21억 개가 될 일은 없다. 충분하다.
📌 핵심: FK로 자주 참조되는 테이블일수록 PK 크기가 중요하다. String(25 bytes) vs Int(4 bytes) — 인덱스 크기가 6배 이상 차이 나고, JOIN 성능에 직접 영향을 준다.
전략 3: 트랜잭션 데이터 → BigInt autoincrement
// ❌ Before (v2.0)
model Assignment {
id String @id @default(cuid())
// ...
}
// ✅ After (v2.1)
model Assignment {
id BigInt @id @default(autoincrement())
// ...
}Assignment, Block, ContentAttempt, ProblemAttempt, DiagnosticSession — 학습 활동 기록 테이블은 BigInt를 썼다.
왜 Int가 아니라 BigInt?
사용자가 매일 학습하면 Assignment, Block, ContentAttempt, ProblemAttempt가 쏟아진다. 사용자 한 명이 하루에 Assignment 1개, Block 5개, ContentAttempt 5개, ProblemAttempt 25개 정도를 생성한다. 사용자 1,000명이면 하루 36,000건. 1년이면 1,300만 건. 서비스가 성장하면?
Int의 21억 한계가 보이기 시작한다. BigInt는 약 920경(9.2 × 10^18)이다. 사실상 무한.
model Block {
id BigInt @id @default(autoincrement())
assignmentId BigInt // FK도 BigInt로 맞춰야 한다
seq Int
// ...
}⚠️ 주의: FK의 타입은 참조하는 PK와 반드시 일치해야 한다. Assignment의 PK가 BigInt면, Block의
assignmentId도 BigInt여야 한다. 이걸 안 맞추면 Prisma가 마이그레이션 시점에 에러를 뱉는다.
FK 연쇄 변경 — 생각보다 큰 파급력
PK 타입을 바꾸면, 그 PK를 FK로 참조하는 모든 곳을 바꿔야 한다.
Academy의 PK가 String → Int로 바뀌면:
// User.academyId
academyId Int? // String? → Int?
// AcademyOwner.academyId
academyId Int @unique // String → Int
// Teacher.academyId
academyId Int // String → Int
// Student.academyId
academyId Int // String → Int
// Class.academyId
academyId Int // String → Int이런 식으로 한 테이블의 PK를 바꾸면 5~10개 FK가 연쇄로 바뀐다. 커밋 #11의 diff가 +1,297줄, -69줄인 이유다. 스키마 변경 자체는 118줄이었지만, seed 코드까지 전면 수정해야 했다.
🌱 seed 데이터 272건 투입
PK 전략을 바꾼 김에, 그동안 미뤄뒀던 seed 데이터도 대량 투입했다.
// Level: 31개 (CSV 데이터 기반)
const levels = [
{ level: 1, name: 'L1', description: '수 세기(0부터 9까지)',
curriculum: '초1-1] 1단원',
metricWeights: { MATRIX_REASONING: 70, QUANTITATIVE_REASONING: 10, ... } },
// ... 31개
];Level 모델에 description, curriculum, metricWeights 필드를 추가하고, 실제 교육과정 기반의 seed 데이터를 넣었다. 레벨마다 5개 성과 지표의 가중치가 다르다.
Level 31개 + ContentItem 19개 + ContentPlayableLevel 158개 + ContentMetricTag 95개
= 총 303건의 seed 데이터seed를 넣고, prisma/verify-seed.ts라는 검증 스크립트까지 만들었다. 각 테이블의 레코드 수가 예상과 맞는지 확인하는 간단한 스크립트다.
✓ Levels: 31
✓ ContentItems: 19
✓ ContentPlayableLevels: 158
✓ ContentMetricTags: 95🔍 단서: seed 데이터를 넣는 과정에서 PK 전략의 문제를 발견하는 경우가 많다. “이론적으로 맞는 설계”와 “실제 데이터가 들어갔을 때”는 다르다. seed를 미루지 말자.
seed 검증까지 통과. 커밋 #12를 찍었다.
test :: seed 데이터 검증 완료 및 변경내역 문서 업데이트여기까지는 순조로웠다.
🔥 커밋 #13: BigInt의 복수 — JSON 직렬화 버그
커밋 #12까지 끝내고 Swagger를 붙여서 API 테스트를 시작했다. Level 목록 조회, ContentItem 조회 — 잘 된다. Int PK의 응답이 깔끔하다.
그런데 ContentPlayableLevel을 조회하는 순간, 문제가 터졌다.
TypeError: Do not know how to serialize a BigIntJavaScript의 JSON.stringify()는 BigInt 타입을 처리하지 못한다.
// 이건 된다
JSON.stringify({ id: 42 }) // '{"id":42}'
// 이건 안 된다
JSON.stringify({ id: 42n }) // TypeError: Do not know how to serialize a BigIntContentPlayableLevel의 PK를 BigInt로 만들었기 때문에, Prisma가 반환하는 id 필드가 JavaScript BigInt 타입이다. NestJS의 응답 직렬화 과정에서 JSON.stringify()가 호출되고, 바로 터진다.
📌 핵심: BigInt PK를 쓰려면 직렬화 계층에서 별도 처리가 필요하다.
JSON.stringifyreplacer를 커스텀하거나, DTO 변환 시String()으로 감싸거나,@ApiProperty({ type: String })으로 Swagger 스키마를 맞추거나.
근본적인 질문
ContentPlayableLevel은 콘텐츠와 레벨의 N:M 매핑 테이블이다. 매핑이 얼마나 될까?
- 현재 ContentItem 19개 × 평균 8개 레벨 = ~158건
- 콘텐츠가 100개로 늘어도 = ~800건
- 콘텐츠가 1,000개로 늘어도 = ~8,000건
연간 10만 건은 절대 안 된다. 이건 마스터 데이터 성격이지 트랜잭션 데이터가 아니다.
같은 논리로 ClassTeacher(반-운영자 배정)와 ClassStudent(반-사용자 배정)도 재검토했다.
- ClassTeacher: 반 하나에 운영자 1~2명, 분기마다 변경 → 연간 수백 건
- ClassStudent: 반 하나에 사용자 10~30명, 분기마다 변경 → 연간 수천 건
셋 다 BigInt가 필요 없었다.
수정: BigInt → Int 다운그레이드
// ❌ Before (커밋 #11)
model ClassTeacher {
id BigInt @id @default(autoincrement())
// ...
}
model ClassStudent {
id BigInt @id @default(autoincrement())
// ...
}
model ContentPlayableLevel {
id BigInt @id @default(autoincrement())
// ...
}
// ✅ After (커밋 #13)
model ClassTeacher {
id Int @id @default(autoincrement())
// ...
}
model ClassStudent {
id Int @id @default(autoincrement())
// ...
}
model ContentPlayableLevel {
id Int @id @default(autoincrement())
// ...
}3개 Junction Table의 PK를 BigInt에서 Int로 다운그레이드. diff는 겨우 6줄이었지만, 이 6줄 뒤에는 “BigInt를 왜 이 테이블에 썼지?”라는 자기 반성이 있었다.
fix :: 기존 big int pk 일부 변경커밋 메시지가 fix다. feat이 아니라 fix. 처음부터 잘못된 판단이었다는 인정.
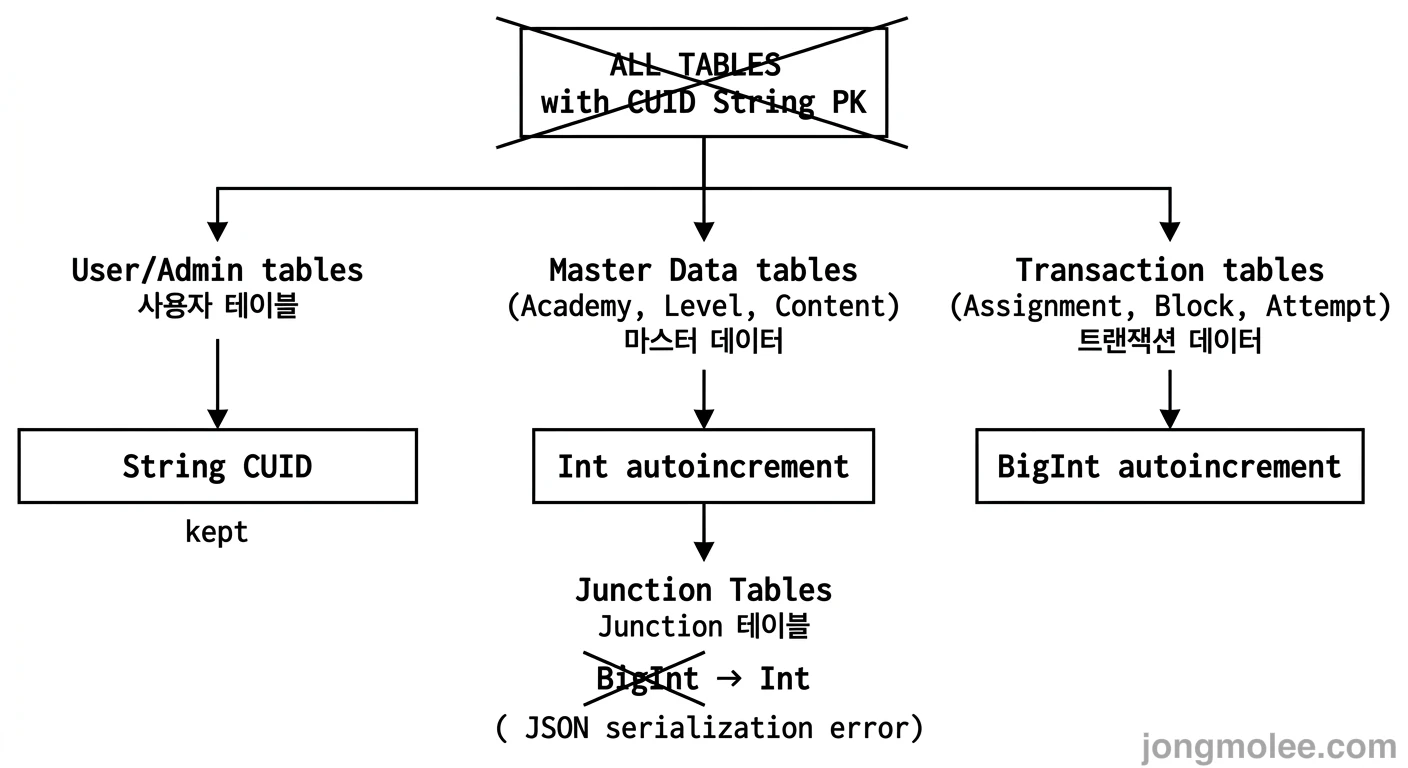
📊 최종 PK 전략 가이드라인
이 경험을 바탕으로 마스터 문서(v1.1.6)에 PK 전략 가이드라인을 추가했다.
PK 타입 선택 기준
| 타입 | 사용 대상 | 연간 예상 레코드 | 예시 테이블 |
|---|---|---|---|
| String CUID | 사용자/인증 테이블 | - | User, Admin, Teacher, Student |
| Int | 마스터 데이터, Junction Table | < 10만 건 | Academy, Level, ContentItem, ClassTeacher |
| BigInt | 트랜잭션, 로그/이력 테이블 | ≥ 10만 건 | Assignment, Block, ContentAttempt, ProblemAttempt |
📌 핵심: 판단 기준은 “이 테이블의 레코드가 Int의 한계(21억)에 도달할 수 있는가?”다. 현재 규모가 아니라 서비스 라이프사이클 전체를 기준으로 판단해야 한다. 하지만 과하게 BigInt를 쓰면 직렬화 비용, 인덱스 크기, 개발 편의성에서 손해를 본다.
왜 이 기준인가
- Int 범위: 약 21억 (2,147,483,647). 하루 1만 건씩 쌓여도 58년 걸린다.
- BigInt 범위: 약 920경 (9.2 × 10^18). 사실상 무한.
- 인덱스 크기: Int = 4 bytes, BigInt = 8 bytes, String CUID = ~25 bytes.
- 직렬화: Int/String은
JSON.stringify에서 자연스럽게 처리된다. BigInt는 별도 처리가 필요하다.
마스터 데이터 테이블에 BigInt를 쓰면 “안전”하긴 하다. 하지만 필요 없는 안전이다. 그 대가로 JSON 직렬화 문제를 안고 가야 한다.
🔬 놓칠 뻔한 함정들
함정 1: FK 타입 불일치
Academy PK를 String → Int로 바꿨는데, Student의 academyId를 안 바꿨다면?
Error: Type mismatch: column "academyId" is of type text,
but expression is of type integerPrisma는 마이그레이션 시점에 이걸 잡아준다. 하지만 prisma db push로 개발할 때는 조용히 넘어가는 경우가 있다. 마이그레이션 파일을 수동으로 작성할 때 특히 위험하다.
⚠️ 주의: PK 타입 변경 후에는 반드시
prisma validate를 돌려서 FK 정합성을 확인하자.prisma migrate dev를 쓴다면 자동으로 검사하지만,db push워크플로우에서는 누락될 수 있다.
함정 2: BigInt와 JavaScript의 불편한 관계
BigInt를 PK로 쓰는 테이블이 있다면, API 응답에서 항상 직렬화를 신경 써야 한다. 선택지는 세 가지:
// 방법 1: DTO에서 String으로 변환
class AssignmentResponseDto {
@ApiProperty({ type: String })
id: string; // BigInt → String 변환
}
// 방법 2: Global JSON replacer
JSON.stringify(data, (key, value) =>
typeof value === 'bigint' ? value.toString() : value
);
// 방법 3: Prisma middleware
prisma.$use(async (params, next) => {
const result = await next(params);
// BigInt 필드를 재귀적으로 String 변환
return convertBigIntToString(result);
});우리는 방법 1(DTO 변환)을 기본으로 쓰고, Swagger 호환성을 위해 @ApiProperty({ type: String })을 명시하는 방식으로 정착했다.
함정 3: seed 순서와 autoincrement
CUID일 때는 seed 순서가 상관없었다. ID가 랜덤이니까. 하지만 autoincrement로 바꾸면 삽입 순서가 곧 ID다.
// Level seed: sortOrder와 id가 일치하길 기대하지 말 것
const l1 = await prisma.level.create({ data: { name: 'L1', sortOrder: 1, ... } });
// l1.id === 1? 아닐 수도 있다. 이전에 삭제된 레코드가 있으면 2부터 시작.🔍 단서: autoincrement PK는 삭제 후 재삽입하면 번호가 건너뛴다. seed에서
upsert를 쓸 때 ID 값에 의존하는 로직이 있으면 깨질 수 있다. seed 코드에서는 항상name이나unique필드로 참조하자.
📋 정리 — 핵심 요약
| 상황 | 안티패턴 | 권장 패턴 |
|---|---|---|
| 마스터 데이터 PK | ❌ String CUID (과잉 설계) | ✅ Int autoincrement |
| 사용자 테이블 PK | ❌ Int (URL 노출 위험) | ✅ String CUID |
| 트랜잭션 데이터 PK | ❌ Int (범위 한계 위험) | ✅ BigInt autoincrement |
| Junction Table PK | ❌ BigInt (직렬화 비용) | ✅ Int autoincrement |
| FK 타입 | ❌ PK와 다른 타입 | ✅ PK와 동일 타입 필수 |
| BigInt API 응답 | ❌ 그대로 JSON.stringify | ✅ DTO에서 String 변환 |
숫자로 보는 커밋 #11~#13
- 변경된 테이블: 20개 (27개 중 User 계열 5개 + enum/policy 2개 제외)
- FK 연쇄 변경: 30+ 필드
- seed 데이터: 303건 투입 (Level 31 + ContentItem 19 + Mapping 158 + MetricTag 95)
- 소요 시간: 약 4시간 (14:55 → 15:55, 중간에 seed 작업 포함)
- 롤백: Junction Table 3개 BigInt → Int 다운그레이드
하루 만에 끝난 리팩토링이지만, 이때 정한 PK 전략은 이후 4개월간 한 번도 바뀌지 않았다. 초기에 제대로 고민한 덕분이다. 다만 “제대로 고민”하는 데에는 한 번 잘못 설계해본 경험이 필요했다.
CUID로 시작한 건 틀린 게 아니었다. 그냥 모든 테이블에 같은 전략을 적용한 게 잘못이었을 뿐.
📌 핵심: “좋은 PK 전략”은 하나의 타입으로 통일하는 게 아니라, 테이블의 성격에 맞는 타입을 고르는 것이다.
다음 편에서는 seed 데이터를 삭제할 때 FK 순서 때문에 삽질한 이야기를 한다. autoincrement PK로 바꾼 직후에 만난 함정이다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음