27개 테이블의 탄생 — Prisma 스키마 설계기
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
B2B SaaS 백엔드의 Prisma 스키마를 설계한 과정. 인증 → 조직 → 러닝 코어 → 트래킹 순서로 27개 테이블과 15개 enum을 만들면서 겪은 설계 결정과 실수들을 기록합니다.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
도메인 문서 2,486줄을 바탕으로 Prisma 스키마를 설계했다. 인증/조직 9개 → 러닝 코어 17개 → 트래킹/정책 27개 테이블까지, 3단계에 걸쳐 커밋 3개로 완성. User + 역할별 테이블 1:1 분리, String CUID PK, 멀티테넌시 인덱스, N:M 이력 추적 테이블 같은 설계 결정을 내리면서 배운 것들을 정리했다.
🏗️ 문서에서 테이블로
지난 편에서 9일간 도메인 문서를 작성한 이야기를 했다. 마스터 문서, 유즈케이스, 권한 매트릭스까지. 이제 그 문서를 실제 데이터베이스 스키마로 옮길 차례였다.
Prisma를 선택한 이유는 첫 번째 편에서 썼으니, 오늘은 schema.prisma 파일 안에서 벌어진 일에 집중한다.
결론부터 말하면, 3일에 걸쳐 커밋 3개로 27개 테이블과 15개 enum을 만들었다. 하루에 약 9개 테이블 속도. 빠르게 느껴질 수 있지만, 그 전에 문서 작업을 9일 했기 때문에 가능한 속도였다. 문서가 없었으면 테이블 하나 만들 때마다 “이 필드가 맞나?” 하면서 멈췄을 거다.
📐 설계 원칙 — 시작 전에 정한 것들
schema.prisma를 열기 전에 몇 가지 원칙을 세웠다.
PK 전략: String CUID
model User {
id String @id @default(cuid())
// ...
}왜 Int auto-increment가 아니라 String CUID?
- 멀티테넌시 안전성: 고객사(테넌트) 간 ID가 충돌할 일이 없다
- URL 노출 안전:
/users/1,/users/2같은 순차 ID는 보안상 좋지 않다 - 마이그레이션 유연성: 나중에 DB를 분리하거나 합칠 때 ID 충돌이 없다
단점도 있다. 인덱스 크기가 커지고, 정렬 시 createdAt을 별도로 써야 한다. 하지만 B2B SaaS에서는 ID 충돌 없는 게 더 중요했다.
사실 이 결정은 나중에 한 번 뒤집어진다. BigInt PK로 갔다가 다시 돌아오는 에피소드가 있는데, 그건 다음 편 이야기.
멀티테넌시 인덱스
모든 테넌트 소속 테이블에 tenantId 인덱스를 넣었다.
model Member {
// ...
tenantId String
@@index([tenantId])
@@index([tenantId, currentLevelId])
@@map("members")
}단순 @@index([tenantId])뿐 아니라, 자주 쓸 쿼리 패턴을 미리 예측해서 복합 인덱스도 추가했다. tenantId + currentLevelId 같은 건 “특정 고객사에서 특정 등급 사용자를 조회”하는 경우. 이런 쿼리는 반드시 나온다.
테이블명 컨벤션
@@map("class_operators") // snake_casePrisma 모델명은 ClassOperator (PascalCase), 실제 테이블명은 class_operators (snake_case). @@map()으로 분리했다. 코드에서는 TypeScript 컨벤션을 따르고, DB에서는 SQL 컨벤션을 따르는 거다.
🔑 Phase 1: 인증과 조직 — 9개 테이블
첫 번째 커밋. User + 역할별 테이블 구조를 잡았다.
User + 역할 테이블 1:1 분리
가장 먼저 고민한 건 사용자 모델이었다. 역할이 4개나 된다:
- PLATFORM_ADMIN: 시스템 관리자
- ACADEMY_OWNER: 고객사 소유자
- TEACHER: 운영자
- STUDENT: 엔드유저
전부 User 테이블 하나에 넣을 수도 있었다. 하지만 역할마다 필드가 다르다. 관리자는 adminLevel이 필요하고, 엔드유저는 birth, currentLevelId 같은 활동 관련 필드가 필요하다. 전부 한 테이블에 넣으면 nullable 필드 범벅이 된다.
// ❌ Before — 단일 테이블 (nullable 지옥)
model User {
id String @id @default(cuid())
role UserRole
email String? // Admin/Operator만 사용
loginId String? // Member만 사용
adminLevel AdminLevel? // Admin만 사용
birth String? // Member만 사용
currentLevelId String? // Member만 사용
tenantId String? // Admin은 null
// ... 20개 필드 중 절반이 nullable
}// ✅ After — 1:1 분리
model User {
id String @id @default(cuid())
email String? @unique
loginId String? @unique
passwordHash String
role UserRole
tenantId String?
// 역할별 1:1 relation
admin Admin?
tenantOwner TenantOwner?
operator Operator?
member Member?
}
model Member {
id String @id @default(cuid())
userId String @unique
tenantId String
name String
birth String // MMDD
currentLevelId String?
// ... 활동 관련 필드만
}결과: User는 인증 정보만, 역할별 테이블은 도메인 필드만. 각 테이블이 딱 자기 역할에 필요한 것만 가진다.
이 패턴의 단점은 조회할 때 include: { member: true } 같은 조인이 필요하다는 거다. 하지만 nullable 필드 20개짜리 테이블보다는 낫다.
N:M 이력 추적 테이블
반-관리자, 반-유저 관계는 단순 N:M이 아니다. “언제 배정되고 언제 해제됐는지” 이력을 추적해야 한다. 분기 중간에 반이 바뀌는 경우가 있으니까.
model ClassOperator {
id String @id @default(cuid())
classId String
operatorId String
role ClassOperatorRole // MAIN | ASSISTANT
assignedAt DateTime @default(now())
unassignedAt DateTime? // null이면 현재 배정 중
@@index([classId, unassignedAt])
@@index([operatorId, unassignedAt])
}핵심은 unassignedAt 필드다. null이면 현재 배정 중, 값이 있으면 과거 배정. “현재 이 반의 관리자는 누구인가?” 쿼리는:
const currentOperators = await prisma.classOperator.findMany({
where: {
classId: 'some-class-id',
unassignedAt: null, // 현재 배정 중인 관리자만
},
});Prisma의 @relation 대신 명시적 조인 테이블을 쓴 이유가 이거다. 암묵적 N:M(_ClassToOperator)으로는 이력 필드를 넣을 수 없다.
Phase 1 결과물
| 모델 | 역할 |
|---|---|
| User | 인증 정보 (email, passwordHash, role) |
| Admin | 시스템 관리자 |
| TenantOwner | 고객사 소유자 |
| Operator | 운영자 |
| Member | 엔드유저 + 활동 상태 |
| Tenant | 고객사 (멀티테넌트 루트) |
| Class | 수업 반 |
| ClassOperator | 반-관리자 배정 이력 |
| ClassMember | 반-유저 배정 이력 |
9개 테이블, enum 3개 (UserRole, AdminLevel, ClassOperatorRole). 이것만으로도 “누가 어디 소속이고 어떤 권한이 있는지”를 완전히 표현할 수 있다.
📚 Phase 2: 러닝 코어 — 8개 테이블 추가
두 번째 커밋. 도메인의 핵심인 활동 관련 테이블을 추가했다.
등급 체계 — Self-reference
30개 등급이 있고, 각 등급에는 상위/하위 등급이 있다. 트리 구조.
model Level {
id String @id @default(cuid())
name String @unique // "L1", "L2", ...
sortOrder Int @unique // 정렬용
// Self-reference (링크드 리스트)
upperLevelId String?
lowerLevelId String?
upperLevel Level? @relation("LevelHierarchy",
fields: [upperLevelId], references: [id])
lowerLevel Level? @relation("LevelHierarchy",
fields: [lowerLevelId], references: [id])
// 역방향 관계 (Prisma 필수)
upperOfLevels Level[] @relation("LevelHierarchy")
lowerOfLevels Level[] @relation("LevelHierarchy")
}self-reference relation은 Prisma에서 살짝 까다롭다. 같은 relation name을 공유하는 필드가 2개이고, 역방향 관계도 2개 써줘야 한다. 처음에 relation name을 다르게 줬다가 에러가 나서 한참 헤맸다.
나중에 이 1:1 링크드 리스트 구조가 계통도(트리)로 바뀌면서
upperLevelId→upperLevelIds[]배열이 되는데, 그건 한참 뒤의 이야기다.
콘텐츠 + 지표 태그
콘텐츠와 지표의 관계도 흥미로운 설계였다.
model ContentItem {
id String @id @default(cuid())
title String
url String
cooldownDays Int @default(0) // 재노출 제한
weight Int @default(1) // 노출 가중치
isActive Boolean @default(true)
metricTags ContentMetricTag[]
}
model ContentMetricTag {
id String @id @default(cuid())
contentId String
metricCode MetricCode
weight Float // 가중치 (합계 = 1.0)
@@unique([contentId, metricCode])
}하나의 콘텐츠가 여러 지표를 측정하는데, 각 지표에 가중치가 있다. 예를 들어 “카테고리 A” 콘텐츠는 METRIC_A: 0.7, METRIC_B: 0.3 이런 식. @@unique([contentId, metricCode])로 같은 콘텐츠에 같은 지표가 두 번 들어가는 걸 방지했다.
weight의 합이 1.0이어야 한다는 제약은 DB 레벨에서는 강제하지 않았다. Prisma에서 check constraint를 직접 지원하지 않기 때문. 이건 도메인 레이어에서 검증하기로 결정했다. 나중에 DDD 레이어를 도입하면서 이 결정이 맞았다는 걸 확인했다.
숙제 → 블록 → 문제 3계층
활동 구조는 3계층이다:
- Assignment (숙제): 일일 활동 단위. 엔드유저 1명당 하루 1개.
- Block (블록): 숙제 안의 활동 단위. 맞춤형 vs 복습 블록.
- Problem (문제): 블록 안에서 풀 문제들.
model Assignment {
id String @id @default(cuid())
memberId String
status AssignmentStatus
source AssignmentSource // ROLLING | INITIAL
runtimeMinutes Int @default(30)
// ...
blocks Block[]
}
model Block {
id String @id @default(cuid())
assignmentId String
seq Int
blockType BlockType // CUSTOMIZED | REMIND
targetLevelId String
targetMetricCode MetricCode?
selectedContentId String
status BlockStatus // PENDING → READY → IN_PROGRESS → COMPLETED
nextBlockId String? @unique // 롤링 발행: 다음 블록 링크
@@index([assignmentId, seq])
}nextBlockId가 흥미로운 부분이다. 블록은 미리 전부 생성하는 게 아니라, 활동 진행에 따라 롤링 방식으로 다음 블록을 생성한다. 완료된 블록의 결과를 보고 다음 블록의 난이도를 조정하는 구조. 이걸 위해 nextBlockId로 단방향 링크드 리스트를 만들었다.
Phase 2 추가 테이블
| 모델 | 역할 |
|---|---|
| Level | 등급 체계 (30단계, self-reference) |
| ContentItem | 활동 콘텐츠 |
| ContentPlayableLevel | 콘텐츠-등급 N:M |
| ContentMetricTag | 콘텐츠-지표 가중치 |
| Problem | 문제 데이터 |
| Assignment | 일일 숙제 |
| Block | 활동 블록 |
| BlockProblem | 블록-문제 매핑 |
누적 17개 테이블, enum은 AchievementState, BlockType, BlockStatus 등 7개 추가.
📊 Phase 3: 트래킹과 정책 — 10개 테이블 추가
세 번째 커밋. 활동 결과를 추적하고, 정책을 관리하는 테이블들.
배치고사 — 최초 등급 배치
새 엔드유저가 들어오면 배치고사를 치르고, 그 결과로 등급이 결정된다.
model DiagnosticVersion {
id String @id @default(cuid())
versionName String
description String?
isActive Boolean @default(true)
sessions DiagnosticSession[]
}
model DiagnosticSession {
id String @id @default(cuid())
memberId String
versionId String
// 결과
placedLevelId String?
accuracyPct Float?
totalTimeMs Int?
// 관리자 승인 여부
isApproved Boolean @default(false)
approvedBy String?
approvedAt DateTime?
}DiagnosticVersion을 별도 테이블로 분리한 이유: 배치고사 문항 세트가 시간이 지나면서 바뀔 수 있다. 버전을 추적해야 “이 사용자는 v2 기준으로 L5에 배치됐다”를 알 수 있다.
isApproved + approvedBy 조합은 관리자 승인 플로우를 위한 것. 진단 결과가 나와도 관리자가 확인하기 전까지는 적용하지 않는 옵션. PlacementPolicy enum으로 IMMEDIATE와 APPROVAL 모드를 지원했다.
등급 조정 이벤트 로그
등급이 바뀌는 건 중요한 이벤트다. 왜 바뀌었는지 추적해야 한다.
enum AdjustmentReason {
DOWN_POOR // 연속 부진 → 하향
RESTORE // 연속 보통 → 원복
UP_EXCELLENT // 연속 우수 → 상향
UP_TEACHER // 관리자 수동 상향
}
model LevelAdjustmentEvent {
id String @id @default(cuid())
memberId String
fromLevelId String
toLevelId String
reason AdjustmentReason
// ...
}등급 조정은 자동(배치 작업)과 수동(관리자 판단) 두 가지 경로가 있다. AdjustmentReason enum으로 구분해서, 나중에 “자동 조정 알고리즘이 잘 작동하고 있나?” 분석할 수 있게 했다.
교육과정 — 기본값 + 오버라이드
model Curriculum {
id String @id @default(cuid())
levelId String @unique // 등급당 1개
targetItemCount Int // 목표 콘텐츠 수
targetAccuracyPct Float // 목표 정답률
// ...
}
model CurriculumOverride {
id String @id @default(cuid())
memberId String
curriculumId String
// 이 유저만의 커스텀 목표
targetItemCount Int?
targetAccuracyPct Float?
// ...
@@unique([memberId, curriculumId])
}기본 진행 트랙은 등급별로 하나. 하지만 특정 사용자에 대해 관리자가 목표를 조정할 수 있다. 기본값 + 오버라이드 패턴. 이건 설정 시스템에서 자주 쓰이는 패턴인데, DB에서도 잘 먹힌다.
조회 로직은 이렇게 된다:
// 해당 유저의 오버라이드가 있으면 그걸, 없으면 기본 교육과정을 사용
const override = await prisma.curriculumOverride.findUnique({
where: {
memberId_curriculumId: { memberId, curriculumId },
},
});
const targetCount = override?.targetItemCount
?? curriculum.targetItemCount;Phase 3 추가 테이블
| 모델 | 역할 |
|---|---|
| DiagnosticVersion | 배치고사 버전 |
| DiagnosticSession | 배치고사 세션 |
| LevelAdjustmentPolicy | 등급 조정 정책 |
| LevelAdjustmentEvent | 등급 변경 이벤트 로그 |
| Curriculum | 등급별 기본 진행 트랙 |
| CurriculumOverride | 사용자별 오버라이드 |
| MemberMetricSnapshot | 지표 스냅샷 |
| ContentAttempt | 콘텐츠 활동 시도 기록 |
| ProblemAttempt | 문제 풀이 기록 |
| Attendance | 활동 기록 |
최종 27개 테이블, enum 15개.
🗺️ 전체 구조 한눈에 보기
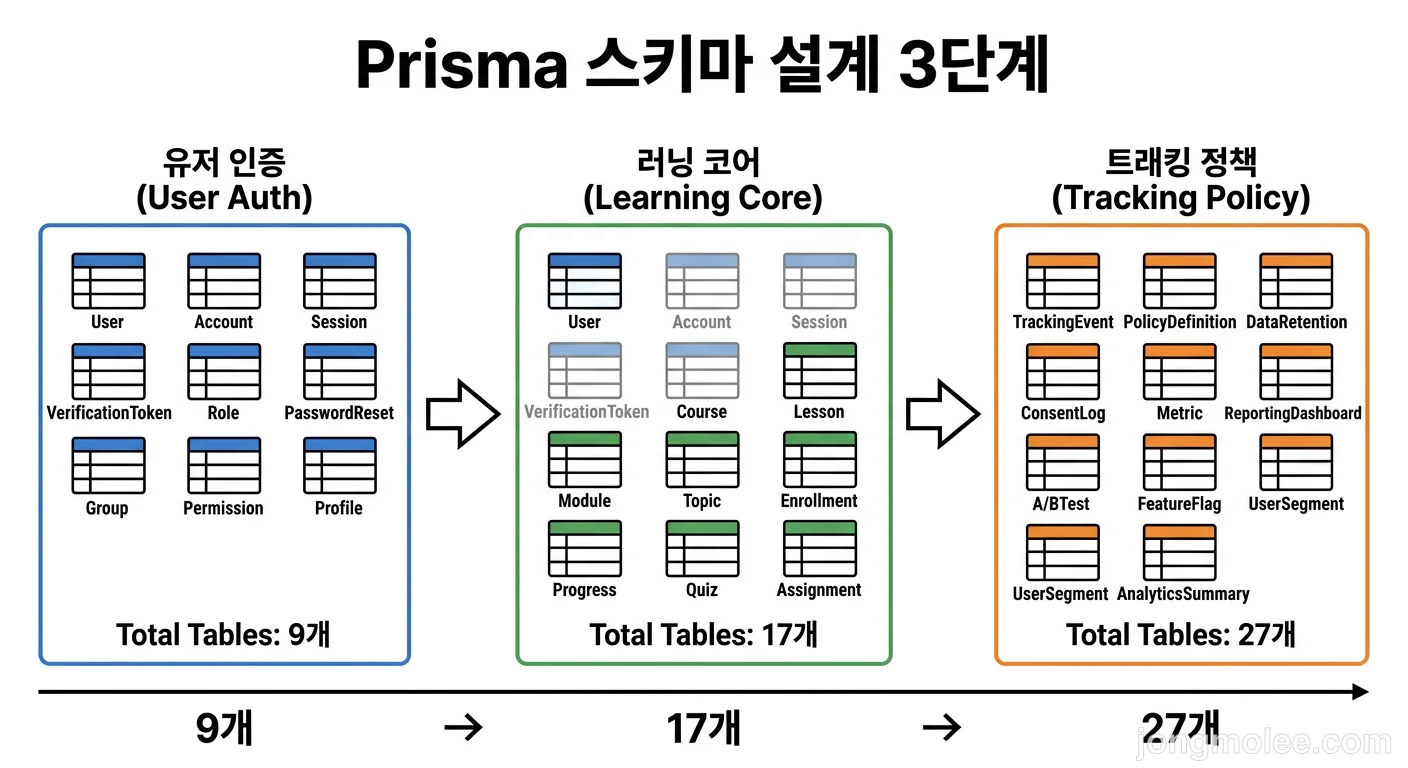
27개 테이블을 4개 도메인으로 나눠보면:
| 도메인 | 테이블 수 | 역할 |
|---|---|---|
| 인증·조직 | 9개 | 누가, 어디 소속인지 |
| 러닝 코어 | 8개 | 뭘 가르치고, 뭘 배우는지 |
| 트래킹 | 6개 | 결과를 어떻게 기록하는지 |
| 정책 | 4개 | 규칙을 어떻게 적용하는지 |
enum은 각 도메인에 흩어져 있는데, 가장 많은 건 러닝 코어 쪽이었다. BlockType, BlockStatus, AssignmentStatus 같은 상태 관련 enum이 많았다.
🤔 설계하면서 내린 주요 결정들
1. Enum vs 참조 테이블
UserRole을 enum으로 할지, 별도 Role 테이블로 할지 고민했다.
// Option A: Enum (선택)
enum UserRole {
PLATFORM_ADMIN
ACADEMY_OWNER
TEACHER
STUDENT
}
// Option B: 참조 테이블
model Role {
id String @id
name String @unique
// ...
}Enum을 선택한 이유: 역할 종류가 4개로 고정이고, 런타임에 추가/삭제될 일이 없다. 참조 테이블은 “사용자가 직접 추가/삭제할 수 있는 값”에 적합하고, enum은 “코드에 하드코딩된 비즈니스 규칙”에 적합하다.
단점: enum 값을 추가하려면 마이그레이션이 필요하다. 하지만 역할 추가는 비즈니스 로직 변경이니까, 마이그레이션이 오히려 맞는 거라고 판단했다.
2. JSON 필드 — 남용하지 않기
Prisma는 Json 타입을 지원한다. 편리하지만 위험하다.
model ContentItem {
// ...
paramsSchemaJson Json? // ✅ 콘텐츠별 파라미터 (구조가 콘텐츠마다 다름)
}
model Level {
// ...
metricWeights Json? // ⚠️ 나중에 이게 문제가 됨
}paramsSchemaJson은 콘텐츠마다 파라미터 구조가 달라서 JSON이 적합했다. 하지만 metricWeights는 처음부터 ContentMetricTag 같은 별도 테이블로 만들었어야 했다. 나중에 이 JSON 필드 때문에 쿼리가 복잡해지는 문제가 생겼다.
교훈: JSON 필드는 “구조가 예측 불가능한 경우”에만 써야 한다. 구조가 정해져 있으면 정규화된 테이블이 항상 낫다.
3. Soft Delete — 나중에 추가
처음 스키마에는 deletedAt 필드가 없었다. “일단 만들고, 필요하면 추가하자”는 생각이었다.
결론부터 말하면, 나중에 추가했고, 전체 쿼리에 deletedAt: null 필터를 넣는 게 정말 고통스러웠다. 이후 별도 편에서 다루겠지만, 지금 돌아보면 처음부터 넣어야 했다. B2B SaaS에서 “삭제” 기능이 없는 서비스는 없으니까.
💥 삽질 로그
Self-reference relation name 충돌
Level 모델의 self-reference를 처음 만들 때:
// ❌ Before — 에러 발생
model Level {
upperLevelId String?
lowerLevelId String?
upperLevel Level? @relation(fields: [upperLevelId], references: [id])
lowerLevel Level? @relation(fields: [lowerLevelId], references: [id])
}Prisma는 같은 모델을 가리키는 relation이 2개 이상이면 relation name을 명시해야 한다. 안 그러면 “ambiguous relation” 에러.
// ✅ After — relation name 추가
model Level {
upperLevelId String?
lowerLevelId String?
upperLevel Level? @relation("LevelHierarchy",
fields: [upperLevelId], references: [id])
lowerLevel Level? @relation("LevelHierarchy",
fields: [lowerLevelId], references: [id])
// Prisma가 요구하는 역방향 relation
upperOfLevels Level[] @relation("LevelHierarchy")
lowerOfLevels Level[] @relation("LevelHierarchy")
}역방향 relation(Level[])까지 2개 써야 한다는 걸 몰라서 한참 삽질했다. Prisma 공식 문서에서 self-relation 부분을 세 번은 읽은 것 같다.
@@unique vs @unique
// 단일 필드 unique
model User {
email String? @unique
}
// 복합 unique (@@unique)
model ContentMetricTag {
contentId String
metricCode MetricCode
@@unique([contentId, metricCode])
}@unique는 단일 필드, @@unique는 복합 필드. 처음에 복합 unique를 @unique로 쓰려다가 안 되어서 찾아봤다. Prisma에서 @는 필드 레벨, @@는 모델 레벨 어트리뷰트다.
🔢 최종 스키마 스탯

모델 (테이블): 27개
Enum: 15개
인덱스: 약 30개 (기본 + 커스텀)
schema.prisma: 928줄
커밋 #8 (Phase 1): 583줄 — 인증/조직 9개 테이블
커밋 #9 (Phase 2): 904줄 — 러닝 코어 8개 추가
커밋 #10 (Phase 3): 928줄 — 트래킹/정책 10개 추가928줄. 한 파일에 전부 담겨 있다. Prisma는 multi-file schema를 지원하지 않던 시절이라(지금은 preview로 지원), 한 파일에서 관리해야 했다. 주석과 섹션 구분(// ====)이 없었으면 못 읽었을 거다.
📝 회고 — 이 스키마가 유지된 기간
이 27개 테이블 구조는 약 3주 정도 유지됐다. 그 사이에 BigInt PK → Int PK 변환(다음 편), seed 데이터 FK 삽질(6편) 같은 에피소드를 거쳤고, 결국 v2.0 대전환(13편~)에서 상당 부분이 바뀌었다.
하지만 기본 골격은 살아남았다. User + 역할 1:1 분리, Tenant 기반 멀티테넌시, N:M 이력 테이블 — 이런 구조적 결정은 v2.0 이후에도 그대로 유지됐다. 잘 바뀌지 않는 부분을 먼저 설계한 게 맞았다.
돌이켜보면 이 3일이 4개월 프로젝트의 뼈대를 잡은 시간이었다. 문서 9일 + 스키마 3일 = 12일. 코드 한 줄 안 치고 12일. 하지만 그 덕에 나머지 3.5개월을 비교적 수월하게 보낼 수 있었다.
다음 편은 BigInt PK에서 Int PK로의 첫 번째 스키마 리팩토링 이야기다. 왜 CUID를 선택해놓고 BigInt를 시도했는지, 그리고 왜 다시 돌아왔는지.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음