Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
📚 교육용 풀스택 SaaS 개발기 시리즈 (23편)
v1.1의 UC-06/07/08/09를 Bundle 기반으로 다시 쓰면서 알고리즘 자체를 새로 썼다. 재작성 도중 리마인드 레벨 역설, 가중치 NaN, POOR 정책 중복이라는 v1.1의 숨은 공백 3개를 발견한 이야기.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- v2.0 마이그레이션은 5-Phase로 쪼갰다. 코드 한 줄 건드리기 전에 문서부터 갈아엎는 게 Phase 1이었다
- Use Case 파일 4개를 전면 재작성했다. UC-06~09 약 900줄 — “Block”을 “Bundle”로 찾아바꾸기한 게 아니라 알고리즘 자체를 새로 썼다
- 재작성 중에 v1.1의 엣지케이스 공백 3개를 발견했다. 리마인드 폴백의 레벨 역설, 가중치 NaN, 미완료 과제의 이중 POOR 판정
- Use Case가 SSoT 역할을 한다. 스키마, Repository, 테스트까지 이후 Phase들이 전부 이 문서에서 파생되기 때문에 여기서 애매하면 다 애매해진다
- 문서 재작성은 코드보다 빠르고 싸다. 타이핑 1
2일 vs 잘못 짠 코드 복구 23주 — 레버리지가 크다
🗺️ 5-Phase 로드맵 — Phase 1이 “문서 정비”인 이유
이전 편에서 v2.0 PRD와 함께 마이그레이션 로드맵 441줄을 짰다는 이야기를 했다. 그 441줄의 실체는 5개 Phase로 쪼갠 실행 계획서인데, 이번 편에서 제일 먼저 정리하고 싶은 건 “왜 Phase 1이 코드가 아니라 문서인가” 이다.
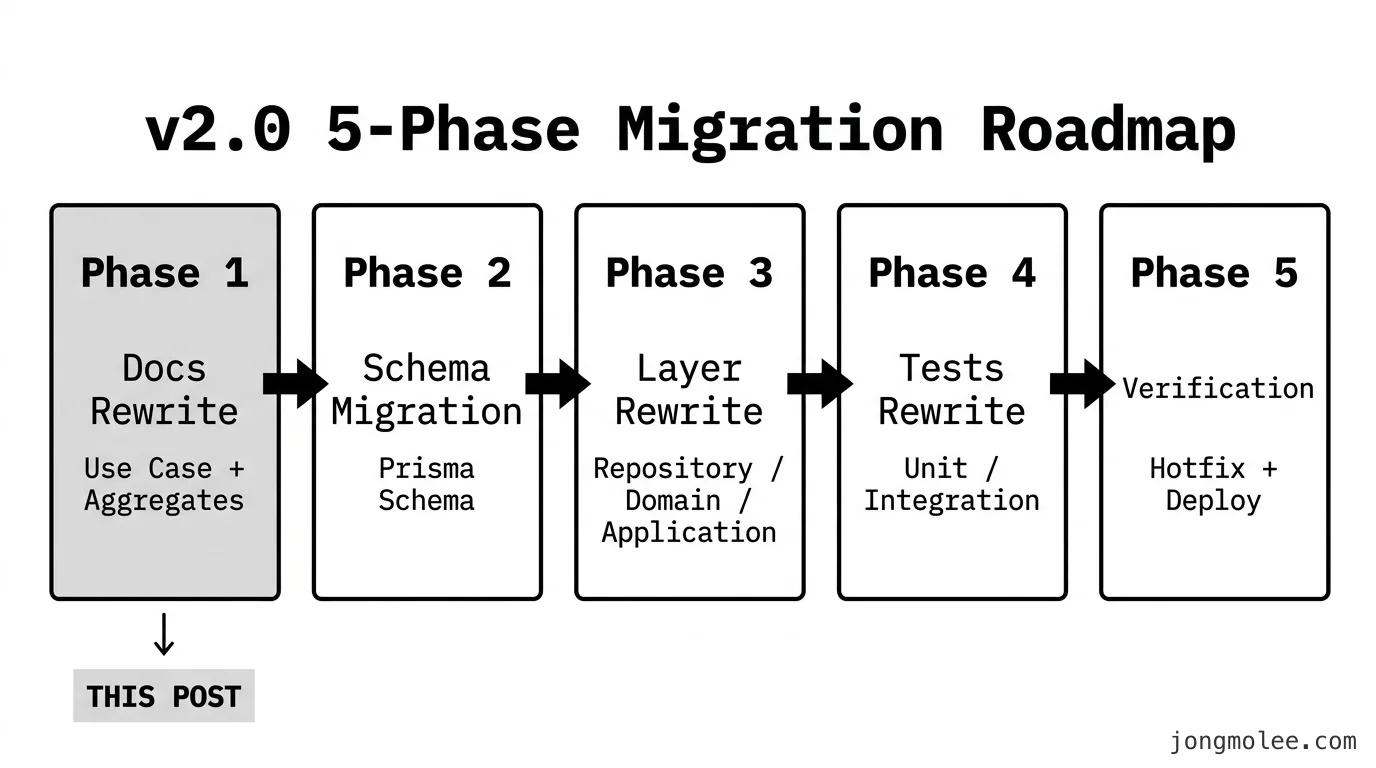
구성은 단순하다.
Phase 1: 문서 정비 (Use Case + Aggregates + 비즈니스 규칙)
Phase 2: Prisma Schema 마이그레이션
Phase 3: 레이어 재작성 (Repository → Domain → Application → Controller → Module)
Phase 4: 테스트 재작성 (단위/통합)
Phase 5: 통합 검증 및 핫픽스Phase 2~5가 기대대로 코드 작업이다. 그런데 Phase 1은 도면만 다시 그리는 단계다. 스키마도 안 건드리고, Repository도 안 바꾸고, 컨트롤러는 쳐다보지도 않는다. “1일 1커밋이면 나머지 Phase가 지연되는 거 아니냐”는 반문이 당연히 들 법한데, 오히려 반대였다.
문서를 먼저 바꾸지 않으면 생기는 일
v1.0 시절에 이미 학습한 내용이었다. 스키마 먼저 바꾸고, Repository 먼저 바꾸고, 컨트롤러 먼저 바꾸면 매번 “근데 정책이 뭐였지?” 라는 질문이 되돌아온다. 그때마다 마스터 문서를 뒤지고, 기획자에게 DM 날리고, 지난주 슬랙을 검색한다. 30분씩 까먹는 이 비용이 하루에 3~4번 반복되면 하루 2시간이 그냥 녹는다.
문서를 먼저 고정하면 이 질문이 사라진다. “Use Case 문서에 명시돼 있으니 그 대로 구현” 이라는 한 줄 규칙이 성립한다. 코드 리뷰도 “Use Case에 맞냐/안 맞냐”로 수렴한다.
📌 핵심: Phase 1은 “문서 정비”라고 쓰지만 실제로는 비즈니스 규칙의 동결 단계다. 이후 Phase들은 동결된 규칙의 기계적 실행에 가까워진다. 설계 결정이 Phase 중간에 뒤집히면 롤백 비용이 폭발한다.
2일 / 3커밋 / 4개 Use Case
결과만 먼저 적어두면 이렇다.
| 커밋 | 내용 | 줄 수 | 시간 |
|---|---|---|---|
| #56 | UC-06 과제 발행 + UC-07 번들 생성 재작성 | +482 / -218 | Day 1 오후 |
| #57 | UC-08 수행 + UC-09 채점 재작성 | +401 / -177 | Day 1 저녁 |
| #58 | 비즈니스 규칙 표 + Cross-UC 일관성 검토 | +219 / -41 | Day 2 오전 |
-218, -177 같은 마이너스가 눈에 띈다. 문서 “추가 작업”인데 기존 내용이 꽤 잘려나갔다는 뜻이다. 단순 치환이 아니라 폐기+재작성이었음을 보여주는 숫자다.
🔍 v1.1 Use Case의 무엇이 문제였나
재작성 전에 v1.1 파일들을 한 번 통독했다. 02-assignment-and-block_v1.1.md 한 파일만 400줄 넘었고, UC-06/07/08/09가 시리즈처럼 엮여 있었다. 통독하면서 세 가지가 눈에 걸렸다.
1. 도메인 언어와 코드 언어가 따로 놀았다
v1.1 UC-07 “블록 생성 알고리즘”의 앞부분은 이렇게 시작한다.
// v1.1 UC-07 step 1
completedCustomizedCount = Assignment.blocks
.filter(b => b.blockType === CUSTOMIZED && b.status === COMPLETED)
.length
if (completedCustomizedCount % 3 === 0) {
blockType = REMIND
} else {
blockType = CUSTOMIZED
}알고리즘 자체는 명확하다. 문제는 독자가 도메인 관점에서 “왜 3개마다?” 를 알 수 없다는 것이다. 3이 매직 넘버다. 문서 다른 장에 가서야 “학습 누적 피로도 완화를 위한 주기”라는 한 줄을 만난다. 규칙이 흩어져 있다.
v2.0 Bundle은 seq 1~5가 구조적으로 STRENGTH → WEAKNESS → WEAKNESS → AVERAGE → AVERAGE 역할에 바인딩되어 있어서, 이런 조건문이 아예 사라진다. 코드를 읽는 순간 “왜” 가 이미 드러난다.
2. 폴백 전략이 명시됐지만 엣지 케이스가 빠졌다
v1.1 UC-07 2.4절의 폴백 4단계는 엔지니어 눈에 꽤 치밀해 보였다.
폴백 1: 지표 유사군 (관련 지표)
폴백 2: 지표 무시 (레벨만)
폴백 3: 레벨 ±1
폴백 4: 검수 대기 큐그런데 “폴백 4에 도달했을 때 유저가 기다리는 동안 화면에는 무엇이 떠야 하나?” 라는 UX 결정이 빠져 있었다. 개발자 관점에서는 “큐에 넣었다” 로 끝이지만, 유저는 버튼을 눌렀는데 아무 일도 안 일어나는 상태를 겪는다. 3초 넘어가면 앱이 죽은 줄 안다. 재작성할 때 이걸 Use Case에 박아 넣어야 했다.
3. Cross-UC 일관성이 암묵적이었다
UC-08의 step 8은 assignment.generateNextBlock() 을 호출한다. 이 호출이 UC-07로 이어지는 진입점이다. 그런데 UC-07 문서 어디에도 “나는 UC-08 step 8 또는 UC-06 step 2에서 호출된다” 는 정보가 없다. 콜 그래프를 문서 읽는 사람이 직접 추적해야 한다. 비즈니스 규칙 하나를 확인하려고 4개 UC를 왔다갔다 해야 하는 비효율이 쌓인다.
⚠️ 주의: “치환하면 될 것 같은데” 라는 느낌은 거의 항상 함정이다. v1.1 → v2.0에서 “Block → Bundle” 만 바꾸면 되겠지 싶었지만, 10분쯤 손대 보면 도메인 규칙 자체가 달라져서 문장을 통째로 다시 써야 했다.
🛠️ UC-07을 번들 기반으로 다시 쓰다 — 패턴 판단 로직을 지우는 일
재작성 중 가장 많이 줄어든 섹션이 UC-07의 패턴 판단 이었다. v1.1은 “맞춤 3개마다 리마인드 1개” 라는 시간 축 패턴을 가지고 있었는데, v2.0 Bundle은 이걸 아예 없앤다.
❌ Before — v1.1 UC-07 (Block 패턴 기반)
// v1.1: 블록 타입 결정
completedCustomizedCount = Assignment.blocks
.filter(b => b.blockType === CUSTOMIZED && b.status === COMPLETED)
.length
if (completedCustomizedCount % 3 === 0) {
blockType = REMIND
targetLevel = random(lowerLevels) // 하위 레벨 중 랜덤
targetMetric = null // 지표 미지정
} else {
blockType = CUSTOMIZED
targetLevel = Student.currentLevelId
targetMetric = Student.weakestMetricCode
// 커리큘럼 상한 체크
if (targetLevel > curriculumTargetLevel) {
targetLevel = curriculumTargetLevel
}
}여기서만 분기가 2개인데, 이 분기 안에서 또 폴백 4단계가 돈다. 문서로 따라가는 사람 입장에서는 조건문이 중첩되니까 상태 머신이 머릿속에 그려지질 않는다.
✅ After — v2.0 UC-07 (Bundle seq 기반)
// v2.0: 번들 내 seq에 따라 역할이 고정
function buildBundleContent(seq: number, ctx: BundleContext) {
switch (seq) {
case 1:
return {
metricType: 'STRENGTH',
targetMetric: ctx.strongestMetricCode,
targetLevel: ctx.currentLevelId,
}
case 2:
case 3:
return {
metricType: 'WEAKNESS',
targetMetric: ctx.weakestMetricCode,
targetLevel: ctx.currentLevelId,
}
case 4:
case 5:
return {
metricType: 'AVERAGE',
targetMetric: ctx.averageMetricCode,
// 레벨링 모듈이 동적으로 설정 (UC-07-A 참조)
targetLevel: ctx.levelingModule.adjustedLevel,
}
}
}조건문이 switch 한 개로 줄었다. 그리고 “왜 이 레벨/지표인지” 가 코드 그 자체 에 있다. 문서의 Business Rules 섹션도 이전엔 10줄이었는데 4줄로 줄었다.
# v2.0 UC-07 Business Rules
1. seq 1은 강점 강화 — 자신감 확보 (metricType=STRENGTH)
2. seq 2~3은 약점 보강 — 핵심 학습 구간 (metricType=WEAKNESS)
3. seq 4~5는 평균 + 레벨링 모듈 결과 반영 (metricType=AVERAGE)
4. 커리큘럼 상한은 모든 seq에 공통 적용 (UC-07-A 참조)레벨링 모듈은 별도 Use Case로 분리했다. UC-07-A 라는 하위 번호를 부여했다. 이전 편의 “번들 안의 미니 피드백 루프” 가 이 UC-07-A의 본체다. Use Case 단위로 쪼개지니까 테스트도 쪼갤 수 있게 됐다.
🔍 단서: 복잡한 알고리즘을 하나의 Use Case에 다 넣으면 문서만 터져나가는 게 아니라, 나중에 단위 테스트 경계를 어디로 잡아야 할지 모호해진다. Use Case를 쪼개놓으면
describe('UC-07-A Leveling Module')같은 이름의 테스트 블록이 자연스럽게 생긴다.
검수 대기 큐를 UC-07-B로 승격
v1.1에서 “폴백 4: 검수 대기 큐” 한 줄이던 로직을 UC-07-B “콘텐츠 검수 큐 관리” 로 별도 Use Case화했다. UX도 여기에 명시했다.
# UC-07-B Main Flow
1. 폴백 1~3 모두 실패 → 검수 큐 엔트리 생성 (status=PENDING)
2. 유저 화면: "새 번들 준비 중" 스켈레톤 UI 2초 지속
3. 2초 내 운영자 개입 없음 → 대체 전략 실행
- 대체 A: 레벨 무시 + 지표 무시 (최후의 콘텐츠)
- 대체 B: 직전 번들 재탕 (중복 플래그 표기)
4. 운영자에게 Slack 알림 발송
5. 검수 완료 후 큐에서 제거v1.1의 암묵적이던 UX 결정이 문서에 박혔다. 이 3줄이 나중에 개발자 A, B가 각자 해석하다가 미묘하게 달라지는 사고를 막는다.
🧩 UC-09 채점 재설계 — POOR 판정과 미완료 처리
UC-09 “블록 채점 및 과제 성취도 판정” 은 v1.1에서도 긴 UC였다. 번들 구조로 바꾸면서 여기도 꽤 많이 잘려나갔다. 핵심은 두 가지 — achievementState 판정 기준의 단일화 와 미완료 번들에 대한 처리 다.
achievementState를 번들 단위로 재계산
// v1.1 UC-09 5.3~5.4
customizedBlocks = assignment.blocks.filter(
b => b.blockType === CUSTOMIZED && b.status === COMPLETED
)
if (customizedBlocks.length < policy.minCustomizedBlocks) {
assignment.achievementState = INSUFFICIENT
assignment.avgCustomizedAccuracy = null
return
}
avgAccuracy = average(customizedBlocks.map(b => b.accuracyPct))v1.1에서는 customizedBlocks 라는 조건 필터가 들어간다. 리마인드 블록은 정답률 집계에서 제외됐다. 그런데 이 조건은 “리마인드는 유저 부담 경감용” 이라는 도메인 의도가 코드 조건문에 숨어 있는 상태 였다.
v2.0에서는 리마인드 블록 자체가 사라졌으니 이 필터가 통째로 없어진다. 그 자리에 “완료된 Bundle 내 모든 BundleContent 의 정답률 평균” 이 들어간다.
// v2.0 UC-09
const completedBundles = assignment.bundles.filter(
b => b.status === 'COMPLETED'
)
const allContents = completedBundles.flatMap(b => b.bundleContents)
const avg = allContents.length
? mean(allContents.map(c => c.accuracyPct))
: null
assignment.avgAccuracy = avg
assignment.achievementState = judgeAchievement(avg, completedBundles.length)필터가 사라지고, “번들이 5콘텐츠로 고정” 이라는 전제 덕분에 completedBundles.length * 5 가 곧 총 콘텐츠 수다. 분모 예측이 명확해진다.
미완료 번들은 POOR로, 그러나 한 번만
v1.1에는 미완료 과제에 대한 정책이 minCustomizedBlocks 조건 하나뿐이었다. “맞춤 블록이 N개 미만이면 INSUFFICIENT” — 한 가지 경우만 컸다. v2.0 기획에서는 “0 번들 완료 시 POOR + 연속일수 카운터에 반영” 이라는 명확한 요구가 추가됐다.
// v2.0 UC-09 미완료 처리
if (completedBundles.length === 0) {
assignment.achievementState = 'POOR'
assignment.reflectInStreakCounter = true
assignment.reflectInMetrics = false // 지표 갱신은 제외
return
}여기서 재작성하다가 문제를 하나 찾았다. “POOR 3일 연속 → 레벨 하향” 이라는 규칙을 v1.1에서 이미 LevelAdjustmentPolicy 에 박아놨는데, 0 번들 완료 시 POOR 인 경우가 이미 3일 연속에 포함되느냐 별도 카운터냐 가 불명확했다. v2.0에서는 단일 카운터로 통합했다. 기획자와 역질문해서 확정한 부분이다.
📌 핵심: “두 가지 규칙이 우연히 같은 결과를 만드는” 상황은 문서에서 가장 조심해야 한다. 단일 POOR 카운터로 통합하면 레벨 조정 로직이 한 곳에서만 발동되고, A/B 테스트할 때도 개입 지점이 하나로 수렴된다.
⚠️ 재작성 중 발견한 3가지 설계 공백
Use Case를 새로 쓰다 보면 v1.1 원본을 단순히 옮기는 게 아니라, 옮기다가 빈 곳을 발견한다. 이번 Phase 1에서 찾은 공백 3가지를 기록해둔다.
공백 1: 리마인드 폴백의 레벨 역설 (v1.1)
v1.1 UC-07 3.1에서 리마인드 블록 레벨 선택이 이랬다.
lowerLevels = Level.findAllBelow(currentLevel)
if (lowerLevels.length > 0) {
targetLevel = random(lowerLevels)
} else {
targetLevel = currentLevel // 폴백
}문제는 lowerLevels.length === 0 인 경우의 폴백이다. 현재 레벨이 L1 (최하위) 인 유저에게는 리마인드 블록이 “현재 레벨” 로 생성된다. 리마인드는 원래 “과거 복습” 인데, L1 유저에게는 “그냥 맞춤 블록과 동일” 이 된다. 이 경우 리마인드 블록이 학습 피로를 줄여주는 게 아니라 부담을 추가한다.
v2.0에서는 리마인드 블록 자체가 사라지면서 이 역설이 자동으로 해소됐다. 하지만 만약 Bundle 기반에서도 유사 폴백을 두게 되면 같은 함정에 빠질 수 있어서 Use Case 하단에 “리마인드 역설 금지 가이드” 박스로 남겨뒀다.
공백 2: 가중치 NaN (v1.1)
v1.1 UC-07 2.5의 가중치 계산이다.
candidates.forEach(c => {
lastUsedDays = daysFrom(c.lastUsedAt)
c.adjustedWeight = c.weight * (1 + lastUsedDays * 0.1)
})c.lastUsedAt 이 null 인 경우 (처음 출제되는 콘텐츠) daysFrom(null) 이 NaN 을 뱉는다. weight * (1 + NaN * 0.1) === NaN. weightedRandom() 이 NaN 을 섞은 배열을 받으면 구현에 따라 “절대 선택되지 않음” 또는 런타임 에러로 갈라진다. 첫 접속 유저에게 신규 콘텐츠가 안 보일 수 있는 치명적 공백이다.
v2.0 UC-07에서는 lastUsedAt === null 을 명시적으로 daysFrom === 999 로 처리했다. 신규 콘텐츠에 가중치를 오히려 얹어서 노출을 유도한다.
const daysFrom = c.lastUsedAt
? differenceInDays(now, c.lastUsedAt)
: 999 // 미출제 콘텐츠는 최대 가중치
c.adjustedWeight = c.weight * (1 + daysFrom * 0.1)공백 3: 미완료 POOR 의 이중 판정 위험
UC-09에서 0 번들 완료 시 POOR 을 부여하는데, 별도로 achievementState === 'POOR' 인 경우에도 POOR 카운터가 증가한다. 이 두 경로가 겹치면 같은 날 두 번 증가할 수 있었다.
// 위험한 패턴
if (completedBundles.length === 0) {
streakCounter.incrementPoor() // 경로 A
}
if (assignment.achievementState === 'POOR') {
streakCounter.incrementPoor() // 경로 B
}Use Case를 쓰면서 이 두 경로를 합쳤다.
// 통합 후
if (assignment.achievementState === 'POOR') {
streakCounter.incrementPoor() // 단일 경로
}
// 0 번들 완료는 achievementState=POOR 을 이미 설정하므로 여기서만 증가🔍 단서: 같은 결과를 만드는 두 경로가 있으면 한쪽이 다른 쪽을 덮거나, 두 쪽이 모두 실행되는 버그가 언젠가 터진다. “하나의 상태 전이, 하나의 코드 경로” 를 원칙으로 두면 이런 사고가 줄어든다.
📋 정리 — 핵심 요약
Phase 1은 “문서 정비” 라는 이름 안에 도메인 규칙의 동결과 엣지케이스 발굴이 다 들어간 단계였다. 스키마를 건드리기 전에 이 작업을 끝내지 않으면, 뒤에서 생기는 사고가 Phase 5까지 누적된다.
| 산출물 | 줄 수 | 역할 |
|---|---|---|
| UC-06 과제 발행 재작성 | +198 / -92 | 첫 번들 생성 규칙 포함 |
| UC-07 번들 생성 재작성 | +284 / -126 | UC-07-A(레벨링) / UC-07-B(검수 큐) 분리 |
| UC-08 수행 재작성 | +172 / -89 | Bundle 단위 시작/완료 이벤트 |
| UC-09 채점 재작성 | +229 / -88 | achievementState 단일 판정, POOR 단일 카운터 |
| 비즈니스 규칙 통합표 | +219 / -41 | Cross-UC 일관성 검토 |
| 상황 | v1.1 안티패턴 | v2.0 권장 패턴 |
|---|---|---|
| 블록 타입 판단 | ❌ count % 3 매직 넘버 분기 | ✅ seq 가 역할에 바인딩된 switch |
| 리마인드 폴백 | ❌ L1 유저에게 현재 레벨 재출제 | ✅ 리마인드 자체 제거, AVERAGE로 대체 |
| 가중치 계산 | ❌ null → NaN 전파 가능 | ✅ 신규 콘텐츠는 999 로 명시 처리 |
| POOR 카운터 | ❌ 이중 경로(미완료+achievement) | ✅ achievementState 단일 경로 |
| Cross-UC 연결 | ❌ 콜 그래프 독자 추적 | ✅ 호출원/호출처 명시 |
| 검수 큐 UX | ❌ “큐에 넣음” 만 기술 | ✅ 스켈레톤 UI 2초 + 대체 전략 A/B |
다음 편에서는 Phase 2 — Prisma Schema 마이그레이션 이야기를 다룬다. Block 테이블을 Bundle + BundleContent 로 쪼개면서, 운영 데이터를 안 날리고 구조를 바꾸는 방법을 적어두려고 한다.
📚 교육용 풀스택 SaaS 개발기 시리즈 (23편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루