E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
로컬 PostgreSQL에서 잘 되던 E2E 테스트가 Cloud SQL에서 전멸한 이야기. session_replication_role 미지원, 테이블 이름 케이스 불일치, 스키마 필드 누락까지 — 4/8에서 8/8 passing으로 가는 과정을 기록한다.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- Cloud SQL(관리형 PostgreSQL)은
session_replication_role설정을 지원하지 않는다. 로컬에서 되던 FK 무시 TRUNCATE가 통째로 실패한다- Prisma 모델명(PascalCase)과 실제 DB 테이블명(snake_case)은 다르다.
@@map으로 매핑된 실제 이름을 써야 한다- E2E 테스트 데이터 정리는 의존성 역순 +
TRUNCATE CASCADE가 정답이다. 트랜잭션으로 감싸면 원자성도 보장된다- 스키마 필드 불일치는 Prisma 스키마를 기준으로 잡는다. 코드에서 추측하지 말고
schema.prisma를 직접 읽어라- E2E 테스트는 비즈니스 로직 버그도 잡아준다.
approvedAt처리 오류 같은 건 단위 테스트에서 놓치기 쉽다
🤔 발단 — 단위 테스트만으로는 부족하다
이전 편에서 단위 테스트 인프라를 구축하고 257개 테스트를 3.5초에 돌리는 데 성공했다. 통합 테스트도 101개가 실제 DB를 상대로 돌아간다. 그런데 한 가지 빈 곳이 있었다.
단위 테스트는 Mock 기반이라 “코드가 의도대로 동작하는가”만 검증한다. 통합 테스트는 Repository 레이어만 실제 DB를 쓴다. API 엔드포인트부터 DB까지 전체 흐름을 관통하는 테스트는 없었다.
유저 등록 → 배치고사 → 등급 배치 → 태스크 생성. 이 온보딩 플로우가 실제로 돌아가는지 확인하려면 E2E 테스트가 필요했다.
📌 핵심: 단위 테스트 커버리지가 높아도 E2E 없이는 “모듈 간 연결”을 검증할 수 없다. Mock이 현실을 반영하지 않으면 테스트는 통과하지만 프로덕션에서 터진다.
🔧 첫 구현 — 로컬 PostgreSQL 기준으로 작성
E2E 테스트의 핵심은 테스트 간 데이터 격리다. 각 테스트가 끝나면 DB를 깨끗하게 정리해야 다음 테스트에 영향을 주지 않는다.
처음에는 PostgreSQL의 session_replication_role 기능을 활용했다.
// test/e2e-setup.ts — 초기 버전
afterEach(async () => {
const tableNames = [
'EventOutbox',
'EventStore',
'Attendance',
'TeacherClassAssignment',
'Student',
'ContentItem',
'Level',
'Academy',
];
// FK 제약 조건 비활성화
await prisma.$executeRawUnsafe('SET session_replication_role = replica;');
for (const tableName of tableNames) {
await prisma.$executeRawUnsafe(
`TRUNCATE TABLE "${tableName}" RESTART IDENTITY CASCADE;`,
);
}
// FK 제약 조건 복원
await prisma.$executeRawUnsafe('SET session_replication_role = DEFAULT;');
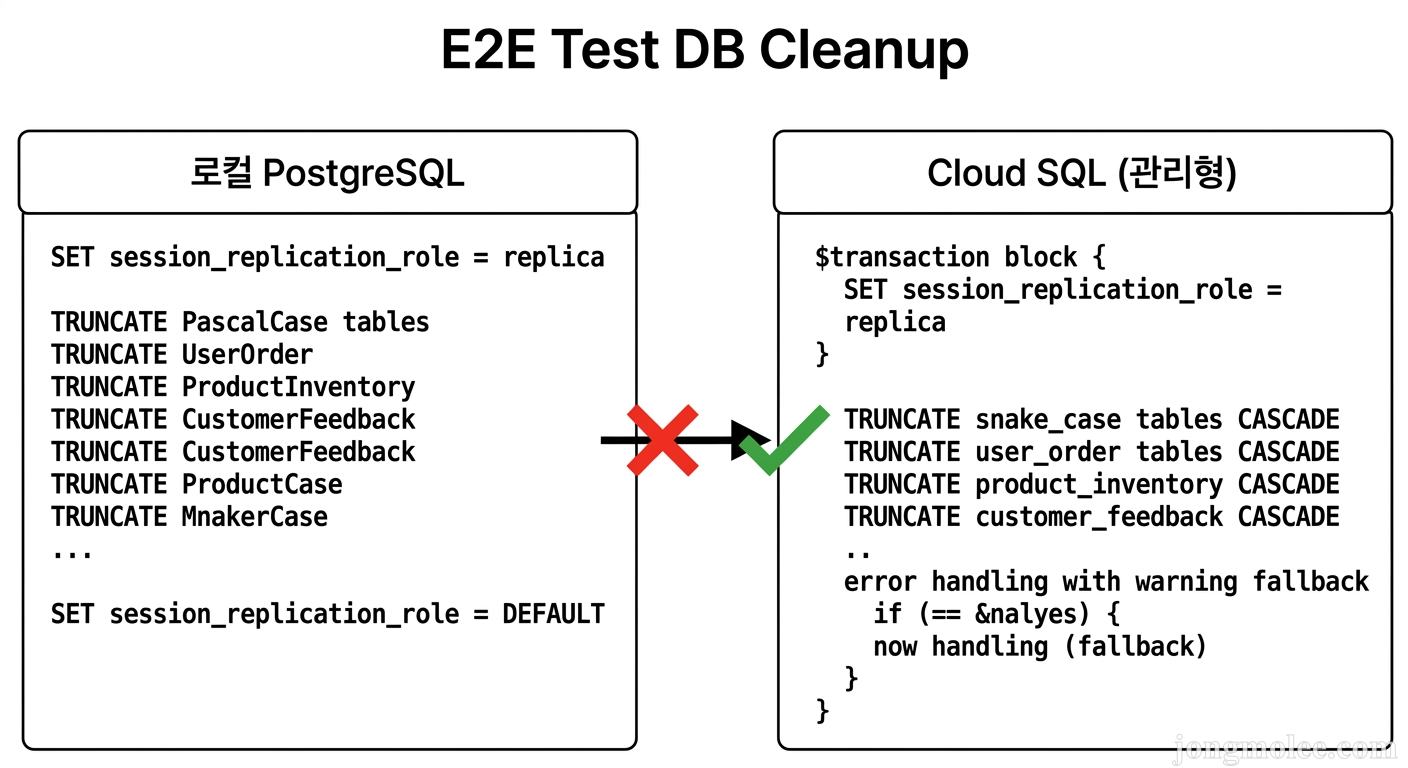
});session_replication_role = replica로 설정하면 PostgreSQL이 FK 트리거를 무시한다. 덕분에 테이블 순서를 신경 쓰지 않고 TRUNCATE할 수 있었다.
로컬에서 8개 테스트 전부 통과. “이제 Cloud SQL에 연결해서 돌리면 되겠지.”
🔥 함정 1: session_replication_role — Cloud SQL이 거부한다

Cloud SQL에 연결하자마자 전멸했다.
Error: permission denied to set parameter "session_replication_role"Cloud SQL은 GCP가 관리하는 PostgreSQL 인스턴스다. 슈퍼유저 권한이 없다. session_replication_role은 슈퍼유저 전용 설정이라 일반 유저로는 변경할 수 없다.
⚠️ 주의: 로컬 PostgreSQL에서
postgres계정으로 개발하다 보면 이런 권한 차이를 놓치기 쉽다. 관리형 DB 서비스(Cloud SQL, RDS, Azure Database)는 슈퍼유저 기능 일부를 차단한다.
해결 방법은 간단했다. FK 트리거를 끄는 대신, 의존성 역순으로 정리하면 된다. 자식 테이블을 먼저 TRUNCATE하면 FK 위반이 발생하지 않는다. 추가로 CASCADE 옵션과 트랜잭션으로 안전성을 확보했다.
// ✅ After — Cloud SQL 호환 버전
afterEach(async () => {
const tableNames = [
'problem_attempts', // 최하위 자식부터
'content_attempts',
'blocks',
'assignments',
'diagnostic_sessions',
'class_students',
'class_teachers',
'students',
'teachers',
'users',
'problems',
'content_playable_levels',
'content_items',
'diagnostic_versions',
'classes',
'levels',
'academies', // 최상위 부모가 마지막
];
await prisma.$transaction(async (tx) => {
for (const tableName of tableNames) {
await tx.$executeRawUnsafe(
`TRUNCATE TABLE "${tableName}" RESTART IDENTITY CASCADE;`,
);
}
});
});🔍 단서:
TRUNCATE ... CASCADE가 있으니 순서가 상관없지 않냐고? 맞는 말이지만, 의존성 역순으로 정리하면 CASCADE가 일을 덜 한다. 성능 차이는 미미하지만, 의도를 명확히 드러내는 코드가 디버깅할 때 훨씬 낫다.
🧩 함정 2: PascalCase vs snake_case — 테이블 이름이 다르다

session_replication_role 문제를 해결했더니 다음 에러가 기다리고 있었다.
relation "Student" does not existPrisma 모델명은 Student, Academy, ContentItem 같은 PascalCase다. 하지만 실제 DB 테이블명은 students, academies, content_items — snake_case에 복수형이다.
왜 다를까? schema.prisma의 @@map 때문이다.
model Student {
id Int @id @default(autoincrement())
name String
...
@@map("students") // 실제 DB 테이블명
}
model ContentItem {
id Int @id @default(autoincrement())
title String
...
@@map("content_items")
}Prisma의 일반 API(prisma.student.findMany())를 쓸 때는 Prisma가 알아서 매핑해주니까 모른다. 하지만 $executeRawUnsafe로 직접 SQL을 보낼 때는 실제 테이블명을 써야 한다.
초기 코드에서 PascalCase로 쓴 테이블명 20개를 전부 snake_case로 수정했다.
📌 핵심: Prisma에서 Raw SQL을 쓸 때는
@@map으로 매핑된 실제 테이블명을 사용해야 한다. 모델명과 테이블명이 다르다는 걸 잊으면 “relation does not exist” 에러와 친해진다.
🔬 함정 3: 스키마 필드 불일치 — 4/8 passing의 원인

테이블 이름 문제까지 잡으니 드디어 테스트가 움직이기 시작했다. 하지만 8개 중 4개만 통과했다.
✅ UC-01: 유저 등록 (2/2 tests passing)
✅ UC-05: 초기 태스크 (2/2 tests passing)
❌ UC-02: 배치고사 (필드 누락)
❌ UC-03: 등급 배치 (필드 누락)
❌ UC-04: 운영자 승인 (필드 누락)실패 원인은 테스트 데이터 생성 시 필수 필드 누락이었다. 스키마가 진화하면서 필수 필드가 추가됐는데, E2E 테스트 코드는 이전 스키마 기준으로 작성되어 있었다.
고객사 phone 필드
// ❌ Before — phone 없이 생성 시도
const academy = await prisma.academy.create({
data: { name: 'Test Academy', code: 'TEST001' },
});
// Error: null value in column "phone" violates not-null constraint
// ✅ After
const academy = await prisma.academy.create({
data: { name: 'Test Academy', code: 'TEST001', phone: '010-1234-5678' },
});배치고사 버전 필드
// ❌ Before — 존재하지 않는 필드 사용
const diagnosticVersion = await prisma.diagnosticVersion.create({
data: {
versionName: 'v1.0', // 이 필드 없음
scoringRuleJson: {}, // 이 필드도 없음
placementPolicy: PlacementPolicy.IMMEDIATE,
},
});
// ✅ After — 실제 스키마에 맞춘 코드
const diagnosticVersion = await prisma.diagnosticVersion.create({
data: {
versionCode: 'DV001', // 실제 필드명
placementPolicy: PlacementPolicy.IMMEDIATE,
},
});문제 모델 필드
// ❌ Before — 구 스키마 기준
const problem = await prisma.problem.create({
data: {
contentId: content.id,
correctAnswerHash: 'answer1', // 없는 필드
difficultyLevel: 1, // 없는 필드
},
});
// ✅ After — 현행 스키마 기준
const problem = await prisma.problem.create({
data: {
contentId: content.id,
levelId: level.id,
seq: 1,
stem: 'Diagnostic problem 1',
answer: 'A',
},
});⚠️ 주의: E2E 테스트는 스키마 변경에 취약하다. 단위 테스트는 Mock이라 실제 스키마와 무관하지만, E2E는 실제 DB에 데이터를 넣기 때문에 필드 하나 빠져도 터진다. 스키마가 자주 바뀌는 초기에는 이 비용이 크다.
🛠️ 함정 4: 비즈니스 로직까지 건드려야 했다

스키마 불일치를 전부 잡았는데도 UC-03(등급 즉시 배치)과 UC-04(운영자 승인)가 실패했다. 이번에는 테스트 코드가 아니라 프로덕션 코드의 버그였다.
IMMEDIATE 배치에서 approvedAt이 불필요하게 설정됐다
즉시 배치(IMMEDIATE policy)는 운영자 승인 없이 바로 등급을 배정하는 정책이다. 그런데 코드에서 approvedAt: new Date()를 넣고 있었다. “승인” 자체가 없는 플로우에서 승인 시간이 기록되는 건 논리적 모순이다.
// ❌ Before — IMMEDIATE인데 approvedAt을 설정
await tx.student.update({
data: {
currentLevelId: dto.placedLevelId,
levelChangedAt: new Date(),
levelPlacementApprovedAt: new Date(), // 승인 없는데?
},
});
return {
approvedBy: null,
approvedAt: new Date(), // 모순
};
// ✅ After — IMMEDIATE은 승인 개념이 없다
await tx.student.update({
data: {
currentLevelId: dto.placedLevelId,
levelChangedAt: new Date(),
// levelPlacementApprovedAt 제거
},
});
return {
approvedBy: null, // IMMEDIATE: 승인자 없음
approvedAt: null, // IMMEDIATE: 승인 시간 없음
};REQUIRES_APPROVAL → APPROVAL
Enum 값도 코드와 스키마가 달랐다. 코드에서는 PlacementPolicy.REQUIRES_APPROVAL을 쓰고 있었는데, 실제 Prisma Enum은 APPROVAL이었다.
// ❌ Before
placementPolicy: PlacementPolicy.REQUIRES_APPROVAL,
// ✅ After
placementPolicy: PlacementPolicy.APPROVAL,getPendingApprovals의 classId 강제 필수
승인 대기 목록을 조회하는 getPendingApprovals에 classId가 필수 파라미터였다. 하지만 전체 승인 대기 목록을 보고 싶을 때도 있다. optional로 변경했다.
// ❌ Before
async getPendingApprovals(classId: number): Promise<PendingApprovalDto[]> {
// ✅ After — classId 없으면 전체 조회
async getPendingApprovals(classId?: number): Promise<PendingApprovalDto[]> {
const pendingSessions = await this.prisma.diagnosticSession.findMany({
where: {
student: classId
? { classStudents: { some: { classId, unassignedAt: null } } }
: undefined,
approvedAt: null,
diagnosticVersion: { placementPolicy: PlacementPolicy.APPROVAL },
},
...
});
}📌 핵심: E2E 테스트는 “코드가 돌아가는가”뿐 아니라 “비즈니스 로직이 맞는가”까지 잡아준다. 단위 테스트에서는 Mock 기대값을 개발자가 정하니까, 개발자의 잘못된 이해가 그대로 테스트에 반영된다. E2E는 실제 데이터를 넣고 결과를 확인하니까 이런 논리적 오류가 드러난다.
🧪 테스트 데이터 셋업도 진화했다
UC-03과 UC-04 테스트가 실패한 또 다른 원인은 데이터 셋업 부족이었다. 등급 배치 후 태스크가 자동 생성되려면 해당 등급에 연결된 콘텐츠와 문제가 있어야 한다.
beforeEach(async () => {
// ... 유저, 등급, 배치고사 세션 생성 ...
// 태스크 블록 생성에 필요한 콘텐츠 데이터
const content = await prisma.contentItem.create({
data: {
title: 'Test Content',
url: 'http://example.com/content',
paramsSchemaJson: {},
cooldownDays: 0,
weight: 1,
},
});
// 콘텐츠 → 등급 연결
await prisma.contentPlayableLevel.create({
data: { contentId: content.id, levelId },
});
// 문제 생성
await prisma.problem.create({
data: {
contentId: content.id,
levelId,
seq: 1,
stem: 'Test problem 1',
answer: 'A',
},
});
});단위 테스트에서는 “태스크 생성 함수가 호출되었는가”만 확인하면 됐지만, E2E에서는 실제로 콘텐츠 풀에서 문제를 뽑아 블록을 만들어야 한다. 데이터가 없으면 태스크 생성 자체가 실패한다.
✅ 결과 — 8/8 passing, 116초
모든 수정을 적용한 뒤 전체 8개 E2E 테스트가 통과했다.
| 유즈케이스 | 테스트 | 결과 |
|---|---|---|
| UC-01: 유저 등록 | 2개 | ✅ |
| UC-02: 배치고사 | 1개 | ✅ |
| UC-03: 즉시 등급 배치 | 1개 | ✅ |
| UC-04: 운영자 승인 워크플로우 | 2개 | ✅ |
| UC-05: 초기 태스크 생성 | 2개 | ✅ |
| 합계 | 8개 | 100% |
실행 시간은 116초. 단위 테스트(3.5초)에 비하면 33배 느리지만, 실제 DB + API 전체 스택을 관통하니까 당연하다.
이후 추가로 3개 E2E 스펙 파일을 작성해서 태스크 관리(UC-06~10), 등급 조정(UC-11), 활동 기록(UC-18)까지 총 22개 E2E 테스트를 확보했다.
📋 정리 — 핵심 요약
| 함정 | 증상 | 해결 |
|---|---|---|
session_replication_role | ❌ Cloud SQL에서 permission denied | ✅ 의존성 역순 TRUNCATE + CASCADE + 트랜잭션 |
| 테이블 이름 | ❌ relation “Student” does not exist | ✅ @@map 기준 snake_case 실제 테이블명 사용 |
| 스키마 필드 | ❌ not-null constraint violation | ✅ schema.prisma 기준으로 필수 필드 확인 |
| 비즈니스 로직 | ❌ IMMEDIATE인데 approvedAt 설정 | ✅ 정책별 동작 정의 명확히 분리 |
| 데이터 셋업 | ❌ 콘텐츠/문제 없어서 태스크 생성 실패 | ✅ E2E beforeEach에 전체 의존 데이터 셋업 |
로컬에서 잘 되던 코드가 관리형 DB에서 터지는 건 흔한 일이다. 특히 슈퍼유저 권한에 의존하는 코드는 언젠가 반드시 문제가 된다. 처음부터 권한 없이 돌아가는 방식으로 작성하는 게 맞다.
E2E 테스트가 느리고 깨지기 쉬운 건 사실이다. 하지만 이번에 비즈니스 로직 버그 2개를 잡아낸 걸 보면, 단위 테스트와 통합 테스트만으로는 채울 수 없는 구간이 분명히 있다.
다음 편에서는 v1.0의 한계에 부딪혀 전체 구조를 갈아엎기로 결심한 이야기를 다룬다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음