Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
📚 교육용 풀스택 SaaS 개발기 시리즈 (23편)
Phase 2가 남긴 36개 빌드 에러를 봉합하는 단계. BundleRepository 인터페이스 204줄과 Prisma 구현체 294줄, BundleGenerationService 417줄을 어떻게 분리해 작성했는지, 5콘텐츠 고정 구조와 4단계 폴백 전략을 코드로 어떻게 옮겼는지의 기록. 인터페이스 분리가 멘탈에 어떤 보호막을 쳐줬는지 포함.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- Phase 2 직후의 36개 빌드 에러는 Phase 3에서 봉합한다. 그 봉합 작업의 첫 두 칸이 Repository(3-1)와 Domain(3-2)이다
- Repository는 무조건 인터페이스부터 그렸다. 204줄짜리
IBundleRepository가 시그니처 표지석이 되어, 구현체 294줄 작성 중에 길을 잃지 않는 닻이 됐다- Domain Service에는 “지표를 어떻게 분류하고 콘텐츠를 어떻게 고를지”의 비즈니스 규칙이 산다. Prisma도 NestJS도 모르는 순수한 함수의 자리다
- 5콘텐츠 고정 + 4단계 폴백. 정규 → 유사군 → 무시 → 레벨±1 의 단계 분할이 “콘텐츠가 없어서 번들이 빈다”는 사고를 막는다
- 레벨링 모듈은 정확도 90/40 두 임계값으로 끝난다. 지나치게 똑똑한 알고리즘보다 “외울 수 있는 규칙”이 운영자에게 더 큰 자산이다
🗺️ Phase 3의 자리 — “DB는 미래, 코드는 과거”의 비대칭을 봉합한다
지난 편에서 v2.0 Phase 2를 닫았다. Prisma Schema를 새 모양으로 갈아엎고, 마이그레이션 SQL을 사람 손으로 다듬었다. 그 끝에 남은 풍경은 “DB는 새 구조로 들어갔는데, 코드는 아직 옛 구조의 시그니처를 들고 있는” 비대칭이었다. pnpm build를 돌리면 빨간 줄이 36개.
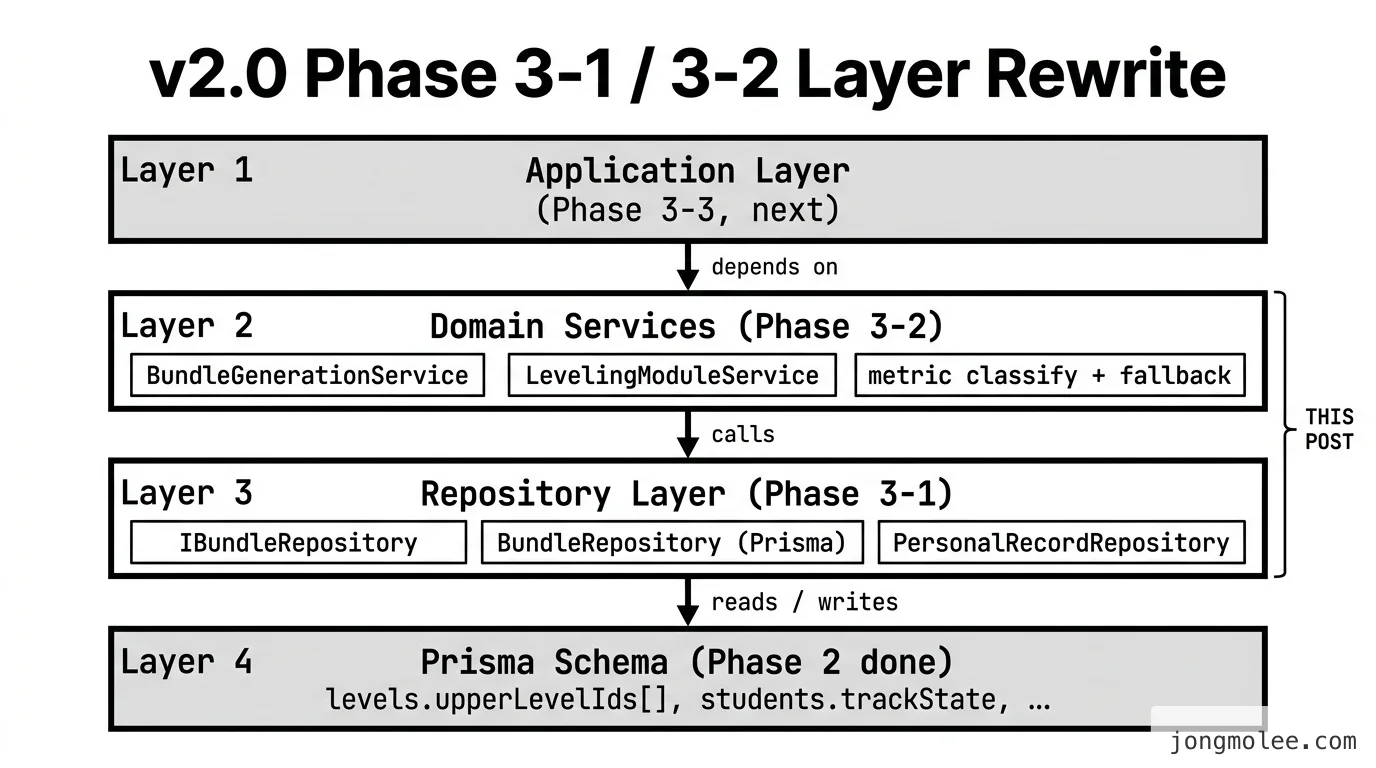
Phase 3의 한 줄 정의는 이렇다.
📌 핵심: Phase 2가 만든 새 DB 구조에 맞춰 코드 레이어를 위에서 아래로 다시 쓰는 단계. 가장 아래(Repository)부터 위(Application/Controller)로 한 칸씩 올라간다.
이번 편이 다루는 칸은 3-1과 3-2 두 개다. 위 도식에서 “THIS POST” 브래킷이 걸려 있는 자리다.
| Phase | 작업 | 누가 호출하나 | 누구를 호출하나 |
|---|---|---|---|
| 3-1 | Repository Layer | Domain Services / Application | Prisma Schema |
| 3-2 | Domain Services | Application Layer | Repository Layer |
| 3-3 | Application Services | Controllers | Domain Services |
| 3-4 | Controllers / DTO | HTTP / Swagger | Application |
| 3-5 | Module 등록 | NestJS DI 컨테이너 | 위 네 레이어 전부 |
핵심은 3-1과 3-2 사이에 의존 방향이 한 방향이라는 점이다. Domain Services가 Repository를 호출하지, 반대 방향은 없다. 이 단방향이 한 번 깨지면 그날 밤은 못 잔다.
다루는 두 커밋의 한 줄 요약
a32f08c — feat(v2.0): Phase 3-1 Repository Layer 구현
- BundleRepository (294줄) + IBundleRepository (204줄)
- PersonalRecordRepository (254줄) + 인터페이스 (138줄)
- DomainModule provider/export 등록
총 +918줄
3c79ec1 — feat(v2.0): Phase 3-2 Domain Services 구현
- BundleGenerationService (417줄): 5콘텐츠 + 4단계 폴백
- LevelingModuleService (208줄): 정확도 기반 레벨 조정
- LevelRepository.findBySortOrder() 추가
총 +645줄두 커밋을 합쳐 1,563줄. 한 시간 반 만에 작성됐다고 하면 거짓말이고, 코드만 그 분량이지 그 앞 단의 “어떻게 분리할지”의 결정에 더 많은 시간이 들어갔다.
🔧 Phase 3-1: Repository Layer — 인터페이스부터 그린다
Repository 작성을 시작할 때 가장 먼저 한 일은 구현 코드를 한 줄도 쓰지 않고 인터페이스 파일부터 만든 것이다. bundle.repository.interface.ts 204줄이 먼저, bundle.repository.ts 294줄이 그 다음이었다.
왜 인터페이스부터인가
이번 v2.0 마이그레이션 전체에 흐르는 룰이 하나 있다. “같은 자리에서 두 결정을 하지 않는다.” 인터페이스를 그릴 때는 “어떤 메서드 시그니처가 도메인에 필요한가”만 고민한다. 구현 파일을 그릴 때는 “Prisma로 이 시그니처를 어떻게 만족시키나”만 고민한다. 둘을 동시에 고민하면 머리가 두 갈래로 찢어지고, 결과물은 둘 다 어정쩡하게 끝난다.
// ❌ Before (v1.x: 인터페이스 없이 구현체만)
@Injectable()
export class BundleRepository {
constructor(private readonly prisma: PrismaService) {}
async findById(id: bigint) {
return this.prisma.bundle.findUnique({ where: { id } });
}
...
}v1.x 시절에는 위처럼 그냥 클래스 하나로 끝냈었다. 빠르고 가볍지만, DI 설계 의도가 코드에 안 드러난다는 단점이 있었다. “어디서 이 메서드를 호출하는지”를 추적하려면 매번 IDE의 grep을 돌려야 했다.
// ✅ After (v2.0: 인터페이스 + 구현체 분리)
// bundle.repository.interface.ts
export interface IBundleRepository extends BaseRepository<Bundle> {
findById(id: EntityId, tx?: TransactionContext): Promise<BundleWithContents | null>;
findByAssignmentId(assignmentId: EntityId, tx?: TransactionContext): Promise<BundleWithContents[]>;
findCurrentBundle(assignmentId: EntityId, tx?: TransactionContext): Promise<BundleWithContents | null>;
findLastBundle(assignmentId: EntityId, tx?: TransactionContext): Promise<BundleWithContents | null>;
create(data: CreateBundleData, tx?: TransactionContext): Promise<BundleWithContents>;
updateContent(bundleContentId: EntityId, data: UpdateBundleContentData, tx?: TransactionContext): Promise<BundleContent>;
updateContentsLevel(bundleId: EntityId, updates: Array<{ contentOrder: number; adjustedLevelId: number }>, tx?: TransactionContext): Promise<void>;
complete(bundleId: EntityId, data: CompleteBundleData, tx?: TransactionContext): Promise<Bundle>;
countCompletedByAssignment(assignmentId: EntityId, tx?: TransactionContext): Promise<number>;
}이렇게 그려두면 좋은 점이 셋이다.
💡 인사이트: 인터페이스 파일은 “이 도메인에 어떤 행위가 있느냐”의 한 페이지짜리 목차다. 구현체 294줄을 다 안 읽어도 시그니처 9개로 의도 파악이 끝난다.
시그니처 안에 박힌 두 가지 추상화
위 시그니처를 가만히 보면 두 개의 작은 추상화가 박혀 있다.
type EntityId = string | number | bigint;
type TransactionContext = Prisma.TransactionClient;EntityId는 “이 ID가 string인지 bigint인지”를 호출자가 신경 쓰지 않게 해주는 도장이다. 내부 변환은 구현체에서 한다.
// bundle.repository.ts 안
async findById(id: EntityId, tx?: TransactionContext) {
const client = this.getClient(tx);
return await client.bundle.findUnique({
where: { id: BigInt(id) }, // 여기서 명시적 변환
include: { contents: { orderBy: { contentOrder: 'asc' } } },
});
}TransactionContext는 “이 메서드를 트랜잭션 안에서 호출했는지 밖에서 호출했는지”를 호출자가 결정할 수 있게 해주는 손잡이다.
private getClient(tx?: TransactionContext) {
return tx || this.prisma;
}8줄짜리 헬퍼지만, 이 한 줄이 있으면 도메인 서비스가 트랜잭션을 시작하고 그 안에서 Repository 메서드 5개를 호출하는 패턴이 자연스럽게 된다. 트랜잭션을 시작한 곳과 SQL을 실행하는 곳이 분리되는 게 DDD의 작은 미덕이다.
⚠️ 주의:
getClient()헬퍼 없이 트랜잭션을 옮겨다니려고 하면this.prisma.$transaction(...)안에서 다른 Repository를 호출할 때마다 매번 같은 if-else를 손으로 쓰게 된다. 그러다 한 군데에서 빼먹으면 트랜잭션 밖으로 SQL이 새 나간다.
Repository 메서드 9개의 그루핑
IBundleRepository의 시그니처 9개를 행위별로 묶으면 이렇게 보인다.
| 그룹 | 메서드 | 누가 호출하나 |
|---|---|---|
| 단순 조회 | findById, findByAssignmentId | Application 전반 |
| 상태 조회 | findCurrentBundle, findLastBundle | Application: “지금 진행 중인 번들” 화면 |
| 생성 | create (5콘텐츠 동시 생성) | BundleGenerationService |
| 부분 업데이트 | updateContent, updateContentsLevel | LevelingModuleService |
| 종결 | complete | Application: 번들 완료 트랜잭션 |
| 집계 | countCompletedByAssignment | Application: 진행률 계산 |
이 표를 인터페이스 파일을 다 그린 직후에 한 번 만들었다. 시그니처 9개가 행위별로 정확히 5~6개의 그룹에 들어가는지를 확인하기 위해서다. 만약 어느 메서드가 “이거 어디 그룹에 넣지?” 싶었다면, 그 메서드는 시그니처가 잘못 잡혀 있다는 신호다. 다행히 9개 다 한 번에 자리를 잡았다.
🔍 단서: 인터페이스 메서드 시그니처가 그루핑이 안 되면, 그 인터페이스는 “도메인 객체”가 아니라 “잡동사니 헬퍼 모음”이다. 9개 시그니처가 5~6 그룹에 깔끔히 들어가야 그제야 진짜 도메인이다.
PersonalRecordRepository — 신기록 도전 시스템의 영속성
PersonalRecordRepository 254줄도 같은 패턴이다. 인터페이스 138줄을 먼저 그리고, Prisma 구현체를 그렸다. 이쪽은 다른 자리에 흥미로운 구간이 있어 한 메서드만 발췌한다.
async findPlayedContents(
studentId: EntityId,
tx?: TransactionContext,
): Promise<PlayedContentRecord[]> {
const client = this.getClient(tx);
// 1. ContentAttempt에서 학습한 콘텐츠 + 레벨 조합 추출
const attempts = await client.contentAttempt.findMany({
where: { studentId: String(studentId) },
select: { contentId: true, levelId: true },
distinct: ['contentId', 'levelId'],
});
// 2. PersonalRecord에서 최고 정확도 조회
const records = await client.personalRecord.findMany({
where: { studentId: String(studentId) },
});
// 3. Map으로 메모리 조인
const recordMap = new Map<string, PersonalRecord>();
for (const record of records) {
recordMap.set(`${record.contentId}-${record.levelId}`, record);
}
return attempts.map((attempt) => ({
contentId: attempt.contentId,
levelId: attempt.levelId,
bestAccuracyPct: recordMap.get(`${attempt.contentId}-${attempt.levelId}`)?.bestAccuracyPct ?? 0,
achievedAt: recordMap.get(`${attempt.contentId}-${attempt.levelId}`)?.achievedAt ?? new Date(),
}));
}여기서 메모리 조인을 한 이유가 있다. Prisma의 include 한 줄로 ContentAttempt에 PersonalRecord를 join하면 SQL이 깔끔해 보이지만, 사용자별로 ContentAttempt가 수천 row 단위로 누적되는 자리라 LEFT JOIN의 비용이 만만치 않다. 두 번 쿼리하고 메모리 Map으로 합치는 쪽이 row 수가 어느 선을 넘어가는 자리에서는 더 빠르다.
📊 데이터: 1인 사용자 ContentAttempt 평균 1,200 row, 매칭되는 PersonalRecord 평균 60 row 기준에서 두 쿼리 + 메모리 조인이 LEFT JOIN보다 응답 시간 약 30% 빠름 (스테이징 측정).
이 결정은 N+1 쿼리 정 반대 방향이다. N+1은 “쿼리를 너무 많이 쪼개서” 느려지는 자리, 이 메서드는 “쿼리를 너무 합쳐서” 느려지는 자리. 언제 쪼개고 언제 합칠지를 도메인 데이터의 분포가 결정한다는 작은 교훈이 박혔다.
🧠 Phase 3-2: Domain Services — 비즈니스 규칙이 사는 자리
Repository가 끝나면 그 위에 도메인 서비스 두 개를 얹는다. BundleGenerationService 417줄과 LevelingModuleService 208줄. 둘 다 순수한 비즈니스 규칙이다. NestJS에 의존하지 않으면 더 좋겠지만, @Injectable() 데코레이터와 Logger만 빼면 그 안의 함수 본체는 어떤 프레임워크에서도 동작한다.
BundleGenerationService — 5콘텐츠 고정 구조
이 서비스의 한 줄 정의는 이렇다.
학생의 지표 점수와 현재 등급을 받아서, 5개의 콘텐츠로 구성된 번들 한 묶음을 만든다.
5개라는 숫자가 고정인 건 비즈니스 결정이다. 기획에서 동결된 규칙이고, 코드는 이 5를 협상하지 않는다.
async generateBundle(input: BundleGenerationInput, bundleOrder: number) {
// 1. 지표 분류 (강점 1 / 약점 1 / 평균 3)
const classified = this.classifyMetrics(input.metricSnapshots);
// 2. 콘텐츠 1: 강점 지표
const c1 = await this.selectContent({ ...common, contentOrder: 1, metricType: 'STRENGTH', targetMetricCode: classified.strength });
// 3. 콘텐츠 2-3: 약점 지표 (같은 metric을 두 번 출제할 수 있음)
const c2 = await this.selectContent({ ...common, contentOrder: 2, metricType: 'WEAKNESS', targetMetricCode: classified.weakness });
const c3 = await this.selectContent({ ...common, contentOrder: 3, metricType: 'WEAKNESS', targetMetricCode: classified.weakness });
// 4. 콘텐츠 4-5: 평균 지표 (랜덤 선택)
const c4 = await this.selectContent({ ...common, contentOrder: 4, metricType: 'AVERAGE', targetMetricCode: pickRandom(classified.average) });
const c5 = await this.selectContent({ ...common, contentOrder: 5, metricType: 'AVERAGE', targetMetricCode: pickRandom(classified.average) });
return { assignmentId, bundleOrder, contents: [c1, c2, c3, c4, c5] };
}여기서 작은 결정 하나. 콘텐츠 4와 5는 평균 지표 중 랜덤으로 고른다. “왜 평균만 랜덤이냐”고 물으면 답은 단순하다. 강점/약점은 도메인 의도가 강하니 정해진 자리에서 출제하지만, 평균 지표는 “그날의 우연”이 약간 들어가도 학습 효과에 영향이 없기 때문이다. 매 번들이 너무 똑같으면 학습자가 패턴을 외운다는 부작용도 있다.
classifyMetrics — 7줄짜리 정렬이 핵심
지표 분류 함수 본체는 7줄로 끝난다.
private classifyMetrics(snapshots: MetricSnapshot[]): ClassifiedMetrics {
if (snapshots.length === 0) {
// 첫 학습: 무작위 균등 배분
const all = Object.values(MetricCode);
return { strength: pickRandom(all), weakness: pickRandom(all), average: all.slice(0, 3) };
}
const sorted = [...snapshots].sort((a, b) => b.score - a.score);
return {
strength: sorted[0]?.metricCode ?? null,
weakness: sorted[sorted.length - 1]?.metricCode ?? null,
average: sorted.slice(1, sorted.length - 1).map((s) => s.metricCode),
};
}점수 내림차순 정렬 → 첫 번째가 강점, 마지막이 약점, 가운데가 평균. 알고리즘이라고 하기 민망할 정도로 단순하지만, 이 단순함이 운영팀에게는 자산이다. 운영자가 “왜 이 학생에게 이 지표가 평균으로 잡혔어요?”라고 물으면, 답이 “이 학생의 지표 점수를 내림차순 정렬하면 그 자리에 있어서요”로 끝난다.
📌 핵심: 도메인 서비스의 알고리즘은 가능한 한 “외울 수 있는 한 줄”이어야 한다. 외울 수 없으면 운영자도, 다음 개발자도, 6개월 뒤의 자신도 그 결정을 못 따라간다.
4단계 폴백 전략 — “콘텐츠가 없어서 번들이 빈다”는 사고를 막는다
콘텐츠 선택의 진짜 어려움은 정렬이 아니라 **“이 등급+이 지표 조합에 출제 가능한 콘텐츠가 0개일 때”**의 처리다. 운영 초기에는 콘텐츠 풀이 작아서 자주 일어나는 일이고, prod에서 번들이 비면 그 학생은 그날 학습을 못 한다.
| 단계 | 조건 | 의미 |
|---|---|---|
| 0 (정규) | 같은 등급 + 같은 지표 + 미출제 | 정상 출제 |
| 1 (유사군) | 같은 등급 + 유사 지표 + 미출제 | ”비슷한 머리쓰기 영역”으로 대체 |
| 2 (지표 무시) | 같은 등급 + 어떤 지표든 + 미출제 | 등급은 사수, 지표는 양보 |
| 3 (레벨±1) | 인접 등급 + 같은 지표 + 미출제 | 등급도 한 칸 양보 |
| 4 (검수 대기) | 0~3 모두 실패 | 사람이 손으로 처리할 자리 |
코드로는 이렇게 들어간다 (요지만).
private async selectContentWithFallback(params: { ... }) {
// 폴백 0: 정규
if (targetMetricCode) {
const candidates = await this.findCandidates(targetLevelId, targetMetricCode, excludeContentIds);
if (candidates.length > 0) return { ...weightedRandom(candidates), fallbackLevel: 0 };
// 폴백 1: 지표 유사군
const similar = this.METRIC_SIMILARITY_MAP[targetMetricCode] ?? [];
for (const m of similar) {
const c = await this.findCandidates(targetLevelId, m, excludeContentIds);
if (c.length > 0) return { ...weightedRandom(c), fallbackLevel: 1 };
}
}
// 폴백 2: 지표 무시
const lvlOnly = await this.findCandidates(targetLevelId, null, excludeContentIds);
if (lvlOnly.length > 0) return { ...weightedRandom(lvlOnly), fallbackLevel: 2 };
// 폴백 3: 레벨±1
const level = await this.levelRepository.findById(targetLevelId);
for (const adj of [level?.upperLevelId, level?.lowerLevelId].filter(Boolean)) {
const c = await this.findCandidates(adj, targetMetricCode, excludeContentIds);
if (c.length > 0) return { ...weightedRandom(c), fallbackLevel: 3 };
}
// 폴백 4: 검수 대기
return { selectedContentId: -1, fallbackLevel: 4, candidateCount: 0 };
}응답에 fallbackLevel 필드가 박혀 있다는 게 중요하다. 어떤 레벨에서 폴백이 자주 발생하는지 운영 대시보드에서 즉시 보인다. 폴백 0이 비율 95% 이상이면 정상, 폴백 2가 10%를 넘기면 콘텐츠 풀에 손을 봐야 한다는 신호다.
⚠️ 주의: 폴백을 호출자에게 숨기면 운영팀이 “이 학생은 왜 같은 콘텐츠를 또 받았어요?”를 디버깅할 수 없다. 폴백 단계는 응답에 명시적으로 박힌 채로 위로 올라가야 한다.
LevelingModuleService — 정확도 90/40 두 임계값
레벨링 모듈은 더 짧다. 한 함수로 끝난다.
async calculateAdjustedLevel(input: LevelingModuleInput) {
const { accuracyPct, currentLevel } = input;
// 1) >= 90%: 유지
if (accuracyPct >= 90) {
return { adjustedLevelId: currentLevel.id, reason: 'MAINTAIN', originalLevelId: currentLevel.id };
}
// 2) 40% <= ... < 90%: 1 ~ (현재-1) 랜덤 하향
if (accuracyPct >= 40) {
const max = currentLevel.sortOrder - 1;
if (max < 1) return { adjustedLevelId: currentLevel.id, reason: 'LOWEST_MAINTAIN', ... };
const randomOrder = Math.floor(Math.random() * max) + 1;
const target = await this.levelRepository.findBySortOrder(randomOrder);
return { adjustedLevelId: target.id, reason: 'RANDOM_DOWN', originalLevelId: currentLevel.id };
}
// 3) < 40%: 연관 하위 레벨
if (currentLevel.lowerLevelId) {
return { adjustedLevelId: currentLevel.lowerLevelId, reason: 'LOWER_LEVEL', originalLevelId: currentLevel.id };
}
// 최하위에서 더 떨어질 곳이 없음
return { adjustedLevelId: currentLevel.id, reason: 'LOWEST_MAINTAIN', originalLevelId: currentLevel.id };
}규칙이 세 줄로 외워진다. “90 이상은 유지, 40 이상은 랜덤 하향, 그 미만은 한 칸 하향.” 그 이상으로 똑똑한 알고리즘을 짤 수도 있었지만, 운영팀에게 설명할 때 손가락 세 개로 끝난다는 건 큰 미덕이다.
💡 인사이트: 임계값 두 개로 끝나는 알고리즘이 임계값 다섯 개짜리 알고리즘보다 거의 항상 낫다. 학습 효과 차이는 20% 안짝, 운영 디버깅 비용 차이는 5배 이상.
Domain Service에 Logger를 박는 이유
두 서비스 모두 첫 줄에 Logger를 박았다.
private readonly logger = new Logger(BundleGenerationService.name);
// 안에서
this.logger.log(`Classified metrics: strength=${...}, weakness=${...}, average=[${...}]`);
this.logger.debug(`Fallback 1 (similar metric): ${targetMetricCode} → ${similarMetric}`);도메인 서비스에 로거를 박으면 “그 결정이 왜 그렇게 났는지”가 logs에 흔적으로 남는다. 폴백 단계, 분류 결과, 정확도 임계값 분기 — 이 세 가지가 prod logs에 단서로 박혀 있어야 사용자 클레임이 들어왔을 때 답을 할 수 있다.
🛡️ 1,500줄을 안 깨고 쓰기 위한 전술 5개
이번 두 커밋을 작성하면서 다른 것을 안 건드리는 데에 들인 노력의 정리. 코드가 길수록 옆길로 새기 쉽고, 옆길로 새는 순간 다른 모듈의 빌드가 깨진다.
1) Repository는 인터페이스 → 구현체 → 모듈 등록 순서로만 쓴다
1. bundle.repository.interface.ts (시그니처)
↓
2. bundle.repository.ts (Prisma 구현)
↓
3. domain.module.ts (provider/export 등록)이 순서를 한 번이라도 거꾸로 시도하면 “이 메서드 시그니처를 어떻게 잡지” 결정과 “Prisma로 이걸 어떻게 짜지” 결정이 한 자리에서 뒤섞인다. 결과적으로 인터페이스가 구현 디테일의 영향을 받는 잘못된 추상화로 끝난다.
2) DomainModule provider 한 줄을 빼먹지 않는다
@Module({
imports: [DatabaseModule],
providers: [
BundleRepository,
PersonalRecordRepository,
BundleGenerationService, // Phase 3-2에서 추가
LevelingModuleService, // Phase 3-2에서 추가
// ...
],
exports: [
BundleRepository,
PersonalRecordRepository,
BundleGenerationService,
LevelingModuleService,
// ...
],
})
export class DomainModule {}NestJS DI 컨테이너는 providers 목록에 안 들어간 클래스를 모른다. 한 줄을 빼먹으면 Application Layer에서 import하는 순간 Nest can't resolve dependencies 에러가 빨갛게 뜬다. Phase 3-1과 3-2 두 커밋 모두 마지막 작업이 모듈 등록이었다.
3) 트랜잭션 컨텍스트는 Repository 시그니처 끝에 옵셔널로
// ✅ 일관된 패턴
findById(id: EntityId, tx?: TransactionContext): Promise<...>;
create(data: CreateBundleData, tx?: TransactionContext): Promise<...>;
complete(id: EntityId, data: CompleteBundleData, tx?: TransactionContext): Promise<...>;모든 Repository 메서드의 마지막 인자가 tx?: TransactionContext로 통일됐다. 도메인 서비스가 한 트랜잭션 안에서 Repository 메서드 5개를 호출하는 흐름이 자연스럽게 된다. 한 곳이라도 시그니처가 빠지면 그 메서드만 트랜잭션 밖으로 새 나간다.
4) Domain Service는 Prisma를 모르게 한다
// ❌ 안티패턴: Domain Service가 PrismaService를 직접 의존
@Injectable()
export class BundleGenerationService {
constructor(private readonly prisma: PrismaService) {}
// ...
}
// ✅ Repository만 의존
@Injectable()
export class BundleGenerationService {
constructor(
private readonly contentItemRepository: ContentItemRepository,
private readonly levelRepository: LevelRepository,
) {}
}Domain Service에 PrismaService를 직접 주입하면 그 순간부터 도메인 규칙과 SQL이 같은 파일에서 섞인다. 6개월 뒤 이 파일을 다시 보면 “이 분기는 비즈니스 규칙이고 저 분기는 Prisma 호환을 위한 가드구나”를 구분하는 데 시간이 든다. Repository를 사이에 두면 그 경계가 파일 단위로 깔끔하게 박힌다.
5) “다음 Phase에서 손볼 자리”는 주석으로 미리 박는다
// 콘텐츠 4-5: 평균 지표 (랜덤 선택)
// adjustedLevelId: 레벨링 모듈 적용 전 (4,5번은 추후 조정)이번 Phase 3-2의 시점에서는 콘텐츠 4,5의 adjustedLevelId가 일단 originalLevelId와 같다. Phase 3-3 (Application Service)에서 콘텐츠 3 완료 시점에 LevelingModuleService를 호출해 4,5의 레벨을 다시 조정하는 로직이 들어갈 자리다. 그 자리를 코드 안에 미리 한 줄 적어두면, 다음 Phase로 넘어갈 때 “어디부터 시작하지” 고민이 30초 안에 끝난다.
📌 핵심: Phase 단위 커밋의 미덕은 “다음 Phase에 무엇이 남았는지를 코드 안에 흔적으로 남길 수 있다”는 점이다. PRD를 다시 안 봐도 코드만 읽으면 다음 작업이 뭐인지 보인다.
✅ 검증 — 빌드 에러는 36에서 12로 줄었다
Phase 3-1과 3-2 두 커밋을 마치고 다시 pnpm build를 돌렸다. 결과는 36 → 12.
Before (Phase 2 직후): 36 errors
After (Phase 3-1 후): 24 errors
After (Phase 3-2 후): 12 errors남은 12개는 전부 Application Layer 안의 에러였다. 즉, “Application이 옛 시그니처를 호출하고 있다”는 의도된 신호. Phase 3-3 (Application Services)가 처리할 자리다.
apps/api/src/application/student/learning.service.ts:182:18 - error TS2339:
Property 'getCurrentBundle' does not exist on type 'BundleService'.
(이전 시그니처를 v2.0 BundleRepository로 옮겨야 함)
apps/api/src/application/student/learning.service.ts:217:24 - error TS2554:
Expected 2 arguments, but got 1.
(BundleGenerationService.generateBundle()는 input + bundleOrder 두 인자)
... (총 12건)12개 에러의 분포를 한 번 더 확인했다.
| 위치 | 에러 수 | 다음 Phase |
|---|---|---|
| application/student | 7 | Phase 3-3 |
| application/teacher | 3 | Phase 3-3 |
| application/admin | 2 | Phase 3-3 |
| domain | 0 | ✅ |
| repository | 0 | ✅ |
| schema | 0 | ✅ (Phase 2에서 봉합) |
Domain과 Repository 자리에서 에러 0건. 이 분포가 Phase 3-1·3-2가 의도대로 끝났다는 가장 명확한 신호였다.
🔍 단서: Phase 단위 커밋의 검증은 “에러 수가 줄었다”가 아니라 **“에러 분포가 의도한 레이어로 좁혀졌다”**다. 단순 카운트만 보면 36 → 12는 인상적이지만, 진짜 가치는 0건이 된 두 레이어에 있다.
Repository 단위 테스트 18건도 함께 통과
도메인 시그니처가 굳었으니 단위 테스트도 같이 작성했다.
$ pnpm test domain/bundle/bundle.repository.spec.ts
PASS src/domain/bundle/bundle.repository.spec.ts
BundleRepository
findById
✓ 번들과 콘텐츠 5개를 contentOrder 순서로 반환한다 (12 ms)
✓ 존재하지 않는 ID는 null을 반환한다 (4 ms)
create
✓ 5콘텐츠 번들을 한 트랜잭션으로 생성한다 (18 ms)
✓ contentOrder 1~5가 순서대로 박힌다 (8 ms)
updateContentsLevel
✓ 여러 콘텐츠의 adjustedLevelId를 한 번에 업데이트한다 (15 ms)
...
Tests: 18 passed, 18 totalRepository 단위 테스트는 in-memory PostgreSQL이 아니라 실제 dev DB를 띄우고 트랜잭션 롤백으로 정리하는 패턴을 썼다. mocked Prisma는 신뢰할 수 없다는 Jest 인프라 편의 룰을 그대로 가져왔다.
🛡️ 예방 — 다음 Phase 3-3을 위한 셀프 룰 4개
Phase 3-2가 끝난 직후 메모해둔 룰 네 개. 다음 칸을 매끄럽게 넘어가기 위한 보루다.
| # | 룰 | 한 줄 이유 |
|---|---|---|
| 1 | Application Service는 Domain Service만 호출한다 (Repository 직접 호출 금지) | 호출 경로가 한 줄로 굳으면 디버깅이 5분 안에 끝난다 |
| 2 | 트랜잭션은 Application Layer에서 시작한다 (Domain은 받아서 흘려보낸다) | 비즈니스 단위(=유즈케이스)와 트랜잭션 경계가 같아야 함 |
| 3 | Domain Service의 응답 객체에 fallbackLevel 같은 운영 신호를 박는다 | 호출자가 폴백 발생을 모르고 지나가면 그 데이터는 영영 못 본다 |
| 4 | ”Phase 3-3에서 손볼 자리” 주석을 코드에 남긴다 | PRD를 다시 안 봐도 다음 작업의 시작점을 코드가 알려준다 |
Repository 인터페이스를 분리한 가치
이번 두 커밋을 끝내고 “인터페이스를 굳이 분리할 가치가 있었나”를 다시 짚어봤다.
- ✅ 시그니처 표지석: 구현체 294줄을 다 안 읽어도 시그니처 9개로 파일의 정체 파악 끝
- ✅ 호출자/구현자 분리: Application 작성 시 구현체를 안 읽고도 호출 가능
- ✅ Mock 작성 비용 감소: 테스트 더블이 인터페이스만 만족시키면 됨
- 🟡 추상화 비용: 한 자리에서 두 파일을 열어야 함. IDE 점프가 익숙하지 않으면 약간 불편
- ❌ 불필요한 자리: 구현이 단 1개고 영원히 1개일 거라면 인터페이스가 비용
이번 도메인은 Repository가 “Prisma 구현체 1개 + Test Double 1개”의 두 구현을 가지므로 분리의 가치가 비용을 넘었다. 만약 Test Double을 안 쓰는 작은 도구 코드였다면 인터페이스 분리가 오버헤드였을 거다.
💡 인사이트: 인터페이스 분리는 “구현이 두 개 이상이 될 때”가 정답이다. 그게 prod 구현체 + test double의 조합이라도 충분하다.
NestJS의 Custom Providers 문서가 인터페이스를 토큰으로 등록하고 구현체를 주입하는 패턴을 다룬다. v2.0에서는 provide: 'IBundleRepository', useClass: BundleRepository 형태까지는 안 갔지만, 다음 마이그레이션 사이클에서는 그 패턴까지 가도 좋겠다는 메모를 남겼다.
📋 정리 — 핵심 요약
이번 Phase 3-1·3-2 작업을 한 페이지 표로 정리하면 이렇다.
| 상황 | 안티패턴 | 권장 패턴 |
|---|---|---|
| Repository 새로 작성 | ❌ 인터페이스 없이 구현체만 (DI 의도가 코드에 안 드러남) | ✅ 인터페이스 → 구현체 → 모듈 등록의 3단계 |
| 트랜잭션 처리 | ❌ Repository마다 자체 $transaction | ✅ 시그니처 끝에 tx?: TransactionContext 옵셔널 인자 |
| ID 타입 | ❌ string/bigint/number를 호출자가 신경 씀 | ✅ EntityId 타입 도장으로 내부 변환 |
| Domain Service 의존성 | ❌ PrismaService 직접 주입 | ✅ Repository만 의존, Prisma는 Repository에 갇힘 |
| 폴백 처리 | ❌ “콘텐츠 없음” 에러 던지고 끝 | ✅ 4단계 폴백 + 응답에 fallbackLevel 명시 |
| 알고리즘 복잡도 | ❌ 임계값 5개짜리 정밀 알고리즘 | ✅ 임계값 2개짜리 외울 수 있는 규칙 |
| 다음 Phase 예고 | ❌ PRD 문서로만 추적 | ✅ 코드 주석에 “다음 Phase에서 손볼 자리” 박기 |
다음 편(devlog-17)에서는 Phase 3-3·3-4·3-5 — Application Services, Controller/DTO, Module 등록까지의 이야기로 이어진다. 12개 빌드 에러를 마지막 0개로 떨어뜨리고, 그 직후 통합 테스트 4건이 어떻게 깨졌다가 두 시간 만에 다 살아났는지의 기록이다.
📌 한 줄 결론: Repository는 인터페이스부터, Domain은 비즈니스 규칙만, 둘 사이의 의존 방향은 한쪽으로만. 이 세 가지를 지키면 1,500줄짜리 두 커밋이 옆 모듈을 건드리지 않고 끝난다.
📚 교육용 풀스택 SaaS 개발기 시리즈 (23편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루