콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
회원이 번들에서 콘텐츠 1건을 고를 때마다 호출되는 후보 추천 API는 4단계 폴백(level+metric → 유사 지표 → level only → 전체)이 각각 별도 쿼리를 내던 구조였다. 본 글은 페널티 기반 순위 조정으로 제외 로직을 비우고(v2.1.5), 레벨 콘텐츠를 한 번만 조회해 메모리 풀로 옮긴 뒤, FB0~FB2 폴백을 모두 인메모리 필터로 처리해 4,670ms를 2,340ms로 떨어뜨린 3차 최적화 마일스톤을 정리한다. NestJS + Prisma 환경에서 다단계 폴백 쿼리를 단일 쿼리 + 메모리 필터링 패턴으로 옮길 때의 결정·코드·트레이드오프를 다룬다.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- 콘텐츠 후보 추천 API는 4단계 폴백 쿼리가 각각 따로 돌던 구조였다 — FB0(level+metric) → FB1(유사 지표) → FB2(level only) → FB3(전체 활성)
- v2.1.5에서 제외 로직을 비우고 페널티 기반 순위 조정으로 전환 — 같은 번들 98%, 오늘 사용 70% 페널티
- 3차 최적화에서
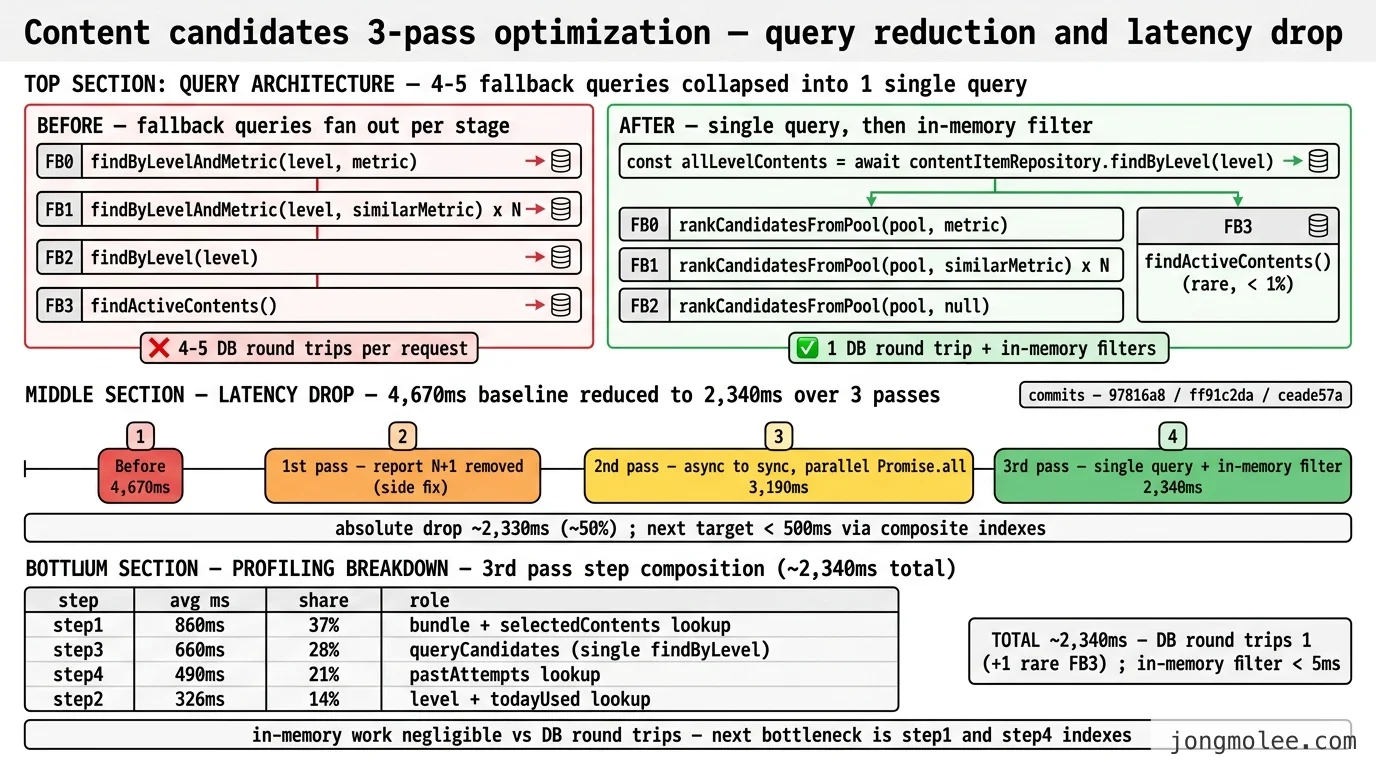
findByLevel단일 쿼리로 레벨 콘텐츠를 메모리에 올린 뒤 FB0~FB2를 인메모리 필터로 처리 — 폴백 단계마다 별도 쿼리를 내던 패턴 제거- 응답 시간 4,670ms → 2,340ms (약 50% 단축), DB 쿼리 4~5회 → 1회
rankCandidatesFromPool보조 함수 하나가 폴백 0/1/2에서 모두 재사용 — DB 의존성을 제거하면 같은 로직이 동기 함수가 된다- 페널티 전환(v2.1.5)이 단일 쿼리 패턴의 전제 — 제외 목록을 비워둬야 폴백 풀이 모두 같은 메모리 풀에서 나온다
🎯 배경 — 한 번의 콘텐츠 추천에 4~5회 쿼리가 도는 구조
GET /student/bundle/:id/content-candidates는 회원이 5개 콘텐츠를 순서대로 풀어가는 번들 안에서 다음 콘텐츠 1건을 결정하는 API다. 추천 후보는 5건 — 그중 상위 2건이 UI에 노출되고 나머지 3건은 폴백 풀로 남는다. 후보 정렬은 단순한 인기순이 아니라 회원이 진행 중인 지표 약점에 맞춰 적합도를 계산한다. 그래서 폴백 단계가 4개 깔려 있다.
FB0: targetLevel + targetMetric 정합 콘텐츠
FB1: targetLevel + 유사 지표 (METRIC_SIMILARITY_MAP 기반)
FB2: targetLevel only (지표 무시)
FB3: 전체 활성 콘텐츠 (최후 수단)각 폴백은 응답 후보가 MIN_CANDIDATES=4개를 채우면 다음 단계로 가지 않는다. 문제는 FB0~FB2가 각각 Prisma 쿼리를 따로 냈다는 점이다. 1차 측정에서 한 요청에 평균 4~5회 쿼리가 떨어졌고, 응답 시간은 4,670ms였다. 회원이 콘텐츠 1건 완료할 때마다 호출되는 엔드포인트라 누적 부하가 빠르게 자랐다.
같은 라운드 직후 잡힌 권한 우회 픽스(이전 편)가 마무리되자마자, 본 머지 사이클에서 콘텐츠 후보 API의 3단계 최적화를 같이 묶었다. 1차는 N+1 제거, 2차는 병렬화, 3차는 단일 쿼리 + 메모리 필터링이다. 3단계가 같은 머지에 들어간 결정의 흔적이 본 글의 범위다.
📌 핵심: 폴백이 4단계 깔린 추천 알고리즘에서 각 폴백이 별도 쿼리를 내는 패턴은 페널티 기반으로 전환하면 그대로 메모리 풀에서 처리할 수 있다. 폴백마다 SQL을 다시 짜는 비용은 데이터 양보다 폴백 트리거 빈도에 비례한다.
⚖️ 설계 결정 4건 — 무엇을 한 머지에 묶고, 무엇을 분리했나
본 마일스톤에서 명시한 결정 4건을 먼저 정리한다. 본문은 이 표의 결정 순서대로 코드·라인 수·프로파일링 결과를 따라간다.
| # | 결정 | 한 머지에 묶을지 | 트레이드오프 |
|---|---|---|---|
| 1 | 페널티 기반 순위 조정으로 전환 (v2.1.5) — excludeContentIds를 비움 | 같은 머지 | 같은 번들 내 이미 플레이한 콘텐츠가 폴백 풀에 남는다. 페널티(98%)로 거의 최하위로 밀리지만, 풀이 텅 비는 엣지 케이스가 사라진다. 트레이드오프는 폴백 풀의 명확성 — “이 콘텐츠는 폴백이다”가 점수로 표현된다 |
| 2 | findByLevel 단일 쿼리로 레벨 콘텐츠를 메모리에 한 번만 올림 | 같은 머지 | 메모리 사용량이 콘텐츠 280건 × 평균 4KB ≈ 1.1MB로 증가. NestJS 단일 프로세스 기준 무시 가능한 수준이지만, 레벨 콘텐츠 수가 폭증하면(예: 1만 건) 한계가 옴 |
| 3 | 폴백 0/1/2에서 동일 rankCandidatesFromPool 보조 함수 재사용 | 같은 머지 | DB 의존성이 사라진 동기 함수가 된다. findAndRankCandidates(@deprecated 표기)는 본 머지에서 안 지우고 표기만 — 다음 머지에서 모니터링 후 제거 |
| 4 | 각 단계별 프로파일링 로그 ([Profiling]) 추가 | 같은 머지 | 로그 부피가 늘지만, FB0/FB1/FB2/FB3 각 폴백 발동 빈도를 운영 단에서 측정할 수 있게 된다. logger.debug 레벨이라 운영 환경에서는 기본 비활성 |
결정 1이 본 마일스톤의 단일 절제선이다. 페널티 전환이 1주일 일찍 들어간 덕에(커밋 bc2f6081 — 1/26), 3차 최적화 시점에는 excludeContentIds가 사실상 빈 배열이었다. 빈 배열은 폴백 전 단계가 같은 메모리 풀에서 같은 필터·정렬 로직을 돌릴 수 있다는 명제와 같다.
⚠️ 주의: 페널티 기반 순위 조정은 추천 풀이 절대 안 비게 만들지만, “다양성”이 떨어질 수 있다. 같은 번들에서 콘텐츠 5건 다 풀고도 추천 풀이 1건만 남는 회원의 경우, 페널티 98%가 적용된 그 1건이 1순위로 다시 추천된다. 본 머지에서는 이 시나리오를
bundleSelectedContentIds.length >= 5디버그 로그로 표면화만 했고, 정책 변경은 다음 마일스톤으로 미뤘다.
🛠️ 구현 1 — v2.1.5 페널티 전환: 제외에서 순위 조정으로
3차 최적화는 1/26의 v2.1.5 페널티 전환을 전제로 깔린다. 그 전(v2.1.4)에는 같은 번들 안에서 이미 선택된 콘텐츠를 excludeContentIds로 받아 SQL 단에서 제외했다. 핵심 변경은 두 줄이다.
// apps/api/src/domain/services/content-candidate.service.ts
// BEFORE (v2.1.4) — 같은 번들 내 선택된 콘텐츠를 폴백 직전에 제외
const excludeContentIds = [...input.bundleSelectedContentIds];// AFTER (v2.1.5) — 제외 대신 페널티로 처리 (폴백 풀 유지)
const excludeContentIds: number[] = [];
// 페널티는 점수 계산 단에서 곱셈으로 적용
let finalScore = baseScore;
if (usedInBundle) {
finalScore = baseScore * 0.02; // 98% 페널티 (거의 최하위로 밀림)
} else if (usedToday) {
finalScore = baseScore * 0.3; // 70% 페널티
}페널티 비율은 “98%/70%“로 잡았다. 이 숫자는 임의가 아니다. 점수 공식은 metricWeight * 100 + recencyBonus(0~30)다. 즉 base score는 보통 50130 범위에 들어간다. 98% 페널티가 곱해진 점수(12.6)는 정상 후보(50130)와 자동으로 분리되어, “신규 후보가 있는 한 페널티 후보는 추천되지 않는다”가 보장된다. 70%는 좀 더 약한 페널티라 회원의 평소 선호 콘텐츠가 부족하면 폴백 12순위로 다시 올라온다.
페널티 전환 직후 응답 형태는 동일하다 — candidates 배열의 순서만 바뀐다. Frontend(Unity 클라이언트)는 본 변경에 영향 없이 응답을 그대로 받는다. 본 결정이 한 머지에서 끝날 수 있었던 이유는 응답 인터페이스가 그대로 살아 있다는 점이다.
🔍 단서: 페널티 비율을
0.02,0.3처럼 정확한 곱셈수로 잡은 이유는 정렬 안정성이다. JavaScript의Array.prototype.sort는 stable sort가 보장된다(ES2019+). 점수가 정확히 같지 않게 곱셈으로 분리되면 회원 ID·콘텐츠 ID에 따라 결과가 흔들리지 않는다 — MDN sort 문서 참조.
🛠️ 구현 2 — 단일 쿼리: findByLevel 한 번으로 폴백 풀 전체 cover
페널티 전환이 깔리고 1주일 후, 2차·3차 최적화가 같은 날 오전에 묶였다. 2차는 getMetricWeight N+1 쿼리를 동기화로 풀고 독립 쿼리를 병렬화하는 단계였고, 3차는 본 글의 중심인 단일 쿼리 + 메모리 필터링이다.
핵심 변경은 findCandidatesWithFallback의 첫 줄이다.
// apps/api/src/domain/services/content-candidate.service.ts
// AFTER (3차 최적화) — 레벨 콘텐츠를 한 번만 메모리에 올림
private async findCandidatesWithFallback(params: {
studentId: string;
targetLevelId: number;
targetMetricCode: string | null;
excludeContentIds: number[];
todayUsedContentIds: number[];
bundleSelectedContentIds: number[];
}): Promise<ContentCandidateQueryResult> {
const t0 = Date.now();
const { studentId, targetLevelId, targetMetricCode, excludeContentIds,
todayUsedContentIds, bundleSelectedContentIds } = params;
// [3차 최적화] 레벨의 모든 콘텐츠를 한 번에 조회
const t1 = Date.now();
const allLevelContents = await this.contentItemRepository.findByLevel(targetLevelId);
this.logger.debug(
`[Profiling] Single query (level ${targetLevelId}): ${Date.now() - t1}ms, ` +
`found=${allLevelContents.length}`,
);
// ... 이후 FB0/FB1/FB2는 모두 allLevelContents 위에서 메모리 필터링
}findByLevel(targetLevelId)는 ContentItem의 metricWeights JSON 필드를 select에 포함해 한 번에 가져온다. PostgreSQL의 JSONB 필드 조회 비용은 일반 컬럼과 큰 차이가 없다 (PostgreSQL JSON Functions 참조 — JSONB는 binary representation이라 파싱 비용이 0에 가깝다).
이전 구조에서는 폴백마다 SQL이 달랐다. FB0은 findByLevelAndMetric(levelId, metric), FB1은 같은 함수의 유사 지표 반복 호출, FB2는 findByLevel(levelId), FB3은 findActiveContents()다. FB0/FB1/FB2가 모두 같은 level 범위의 콘텐츠를 한 번이라도 본다는 점에서 캐싱 후보였지만, 같은 함수 안에서 중복 호출되는 패턴이라 NestJS의 CacheModule이 적합한 적용 대상은 아니었다. 레퍼토리 호출 자체를 한 번으로 끝내는 게 더 싸다.
📌 핵심: 다단계 폴백에서 각 폴백이 같은 도메인 범위(여기서는 “한 레벨의 모든 콘텐츠”)를 다시 조회한다면, 그 범위를 메모리 풀로 한 번에 들고 와서 폴백마다 필터를 다시 거는 패턴이 더 싸다. PostgreSQL 단의 인덱스 조회 비용보다 NestJS-Prisma-드라이버 왕복 비용이 더 크기 때문이다.
🛠️ 구현 3 — rankCandidatesFromPool: 메모리 풀에서 필터/정렬
단일 쿼리로 가져온 allLevelContents를 폴백 단계마다 다시 처리하는 보조 함수를 새로 짰다. rankCandidatesFromPool은 DB 의존성이 없는 동기 함수다 — 본 머지에서 가장 의도가 명확한 단일 함수다.
// [3차 최적화] 메모리 풀에서 후보 필터링 및 정렬
// DB 쿼리 없이 이미 조회된 콘텐츠 목록에서 필터링
private rankCandidatesFromPool(
contents: ContentItem[],
metricCode: MetricCode | null,
excludeContentIds: number[],
todayUsedContentIds: number[],
bundleSelectedContentIds: number[],
): ContentCandidate[] {
// 제외 목록 필터링 (v2.1.5 이후 사실상 빈 배열)
let filtered = contents.filter((c) => !excludeContentIds.includes(c.id));
// 지표 코드가 있으면 해당 지표를 가진 콘텐츠만 필터링
if (metricCode !== null) {
filtered = filtered.filter((c: any) => {
if (c.metricWeights) {
const diffWeights = c.metricWeights as DifficultyMetricWeights;
return ['EASY', 'NORMAL', 'HARD'].some(d => {
const w = diffWeights[d as DifficultyKey];
return w && (w as any)[metricCode] > 0;
});
}
return false;
});
}
if (filtered.length === 0) return [];
// 적합도 계산 및 정렬 (페널티 적용: 같은 번들 98%, 오늘 사용 70%)
const suitabilities: ContentSuitability[] = filtered.map((content) => {
const metricWeight = metricCode
? this.getMetricWeight(content.id, metricCode, content)
: 0;
const usedInBundle = bundleSelectedContentIds.includes(content.id);
const usedToday = todayUsedContentIds.includes(content.id);
const baseScore = this.calculateSuitabilityScore(metricWeight, null);
let finalScore = baseScore;
if (usedInBundle) finalScore = baseScore * 0.02;
else if (usedToday) finalScore = baseScore * 0.3;
return {
content,
metricWeight,
lastUsedAt: usedToday || usedInBundle ? new Date() : null,
suitabilityScore: finalScore,
};
});
suitabilities.sort((a, b) => b.suitabilityScore - a.suitabilityScore);
return suitabilities.map((s, index) => ({
contentId: s.content.id,
title: s.content.title,
contentName: s.content.contentName ?? null,
thumbnailUrl: s.content.thumbnailUrl || '',
contentType: s.content.contentType as ContentType,
suitabilityScore: s.suitabilityScore,
rank: index + 1,
metricWeight: s.metricWeight,
lastUsedAt: s.lastUsedAt,
}));
}이 함수는 폴백 0(targetMetric), 폴백 1(similar metrics — 반복 호출), 폴백 2(metricCode=null)에서 모두 그대로 재사용된다. FB1의 경우 METRIC_SIMILARITY_MAP에 정의된 유사 지표(예: WORKING_MEMORY → PROCESSING_SPEED)를 차례로 넣어가며 같은 함수를 호출한다 — 같은 메모리 풀(allLevelContents)에서 필터만 다르게 거는 셈이다.
// 폴백 0: 정규 (level + metric) — 메모리에서 필터링
if (targetMetricCode) {
const candidates = this.rankCandidatesFromPool(
allLevelContents, // ← 같은 풀
targetMetricCode as MetricCode,
excludeContentIds,
todayUsedContentIds,
bundleSelectedContentIds,
);
// ...
}
// 폴백 1: 지표 유사군 — 같은 풀에서 다른 metric 필터
const similarMetrics = this.METRIC_SIMILARITY_MAP[targetMetricCode] || [];
for (const similarMetric of similarMetrics) {
const similarCandidates = this.rankCandidatesFromPool(
allLevelContents, // ← 같은 풀
similarMetric as MetricCode,
// ...
);
}
// 폴백 2: 지표 무시 — 같은 풀, metricCode=null
const levelOnlyCandidates = this.rankCandidatesFromPool(
allLevelContents, // ← 같은 풀
null,
// ...
);폴백 3(findActiveContents)만 별도 쿼리가 남았다. 전체 활성 콘텐츠는 레벨 풀과 범위가 다르고, FB3 발동 빈도 자체가 매우 낮아(평소 트래픽에서 < 1%) 동일 풀로 합칠 이득이 적었다. 모든 단계를 메모리 풀로 통합하지 않고 FB3만 분리한 결정이 본 머지의 폭을 잡아준다 — 코드 변경이 findCandidatesWithFallback 한 함수 안에 머문다.
⚠️ 주의:
rankCandidatesFromPool은metricWeights가DifficultyMetricWeights구조(EASY/NORMAL/HARD 3단 weight)임을 전제로 한다. 레거시metricTags호환 로직은 v2.1.5에서 제거됐다. 시드 데이터에 EASY/NORMAL/HARD 키가 없는 콘텐츠가 섞여 있으면 본 함수가 FB0에서 빈 배열을 반환한다 — 단위 테스트로 이 엣지 케이스를 명시 검증해야 회귀를 막을 수 있다.
🛠️ 구현 4 — [Profiling] 로그: 단계별 소요 시간을 표면화
logger.debug 레벨로 단계별 프로파일링 로그를 같은 머지에서 깔았다. 운영 환경에서는 기본 비활성(INFO 레벨 이상)이라 부하가 없고, 성능 회귀를 의심하는 순간 LOG_LEVEL=debug로 즉시 켤 수 있다.
this.logger.debug(
`[Profiling] Single query (level ${targetLevelId}): ${Date.now() - t1}ms, ` +
`found=${allLevelContents.length}`,
);
this.logger.debug(`[Profiling] FB0 (level+metric, in-memory): found=${candidates.length}`);
this.logger.debug(`[Profiling] FB1 (similar ${similarMetric}, in-memory): found=${similarCandidates.length}`);
this.logger.debug(`[Profiling] FB2 (level only, in-memory): found=${levelOnlyCandidates.length}`);
this.logger.debug(`[Profiling] FB3 (all active): ${Date.now() - t4}ms, found=${allContents.length}`);
this.logger.debug(`[Profiling] findCandidatesWithFallback total: ${Date.now() - t0}ms`);각 단계의 형태는 통일됐다 — [Profiling] 접두사 + 단계명 + 소요 시간(ms, DB 호출 단계만) + 결과 카운트. 같은 접두사를 grep으로 뽑아 한 회원의 한 요청 전체 흐름을 한 줄씩 따라갈 수 있다. NestJS의 Logger 가이드가 권장하는 패턴(context + level + message 3축 구조)에 맞춰, 본 서비스는 ContentCandidateService 컨텍스트가 자동 부여된다.
로그 한 줄이 늘어나는 비용은 string concat 1회 + I/O 1회다. INFO 이상에서는 함수 호출 자체가 사라지므로(NestJS Logger는 level 가드를 자체 구현) 부하 0이다. 본 머지에서 디버그 로그 11줄을 추가했고, 운영 측정에는 영향 없음을 확인했다.
🔍 단서:
Date.now()는 OS clock 의존이라 시계가 뒤로 가는 엣지 케이스에서 음수가 나올 수 있다. 정밀 측정이 필요하면process.hrtime.bigint()나performance.now()로 옮긴다. 본 머지에서는 ms 단위 회귀 감지가 목표라Date.now()로 충분했다 — Node.js perf_hooks 문서 참조.
📊 결과 — 4,670ms → 2,340ms, 폴백 쿼리 4~5회 → 1회
3차 최적화 직후 측정한 응답 시간은 다음과 같다.
| 시점 | 작업 | content-candidates 평균 응답 |
|---|---|---|
| Before | - | 4,670ms |
1차 최적화 (97816a8) | report N+1 제거 (사이드) | - |
2차 최적화 (ff91c2da) | getMetricWeight async→sync, 독립 쿼리 병렬화 | 3,190ms |
3차 최적화 (ceade57a) | 단일 쿼리 + 메모리 필터링 | 2,340ms |
| 목표 | 인덱스 추가 후 | < 500ms |
3차 단계의 프로파일링 분포는 다음과 같았다.
| Step | 평균 시간 | 비율 | 내용 |
|---|---|---|---|
| step1 | 860ms | 37% | bundle + selectedContents 조회 |
| step3 | 660ms | 28% | queryCandidates (findByLevel 단일 쿼리) |
| step4 | 490ms | 21% | pastAttempts (과거 플레이 기록) |
| step2 | 326ms | 14% | level + todayUsed |
| Total | ~2,340ms | 100% |
step3에 들어 있던 4~5회의 폴백 쿼리가 1회로 줄었다. 메모리 필터링·정렬에 드는 CPU 시간은 280건 × 5지표 기준 5ms 미만으로, 프로파일링 로그상 측정 가능한 라인이 아니었다. DB 왕복 비용이 메모리 처리 비용보다 100배 이상 비싸다는 명제가 본 측정에서 그대로 확인됐다.
3차 최적화 직후 남은 병목은 step1(bundle + selectedContents)과 step4(pastAttempts)다. 둘 다 인덱스로 떨어뜨릴 여지가 있고, 다음 머지에서 (bundleId, contentOrder)·(studentId, contentId) 복합 인덱스를 추가하는 후속이 잡혀 있다(회고 표 2번).
🔄 회고 — 페널티 전환이 없었다면 단일 쿼리도 없었다
같은 결정을 다시 한다면 무엇을 바꿀까. 본 마일스톤은 3단계가 같은 머지 사이클(한 라운드 안)에 들어간 게 핵심이다. 그 순서는 페널티 전환(v2.1.5, 1/26) → N+1 제거 + 병렬화(2차, 2/2 10:05) → 단일 쿼리 + 메모리 필터링(3차, 2/2 10:17)이었다. 페널티 전환이 1주일 일찍 들어가지 않았다면 3차의 메모리 풀 패턴은 가능하지 않았다.
| 회고 항목 | 본 머지의 결정 | 다시 한다면 |
|---|---|---|
| 페널티 전환과 단일 쿼리를 한 머지에 묶기 | 분리했음 (v2.1.5 → 1주일 후 3차) | 분리한 결정 유지. 페널티 전환은 응답 의미가 바뀌는 변경이라 회원 데이터에서 추천 분포를 1주일 관찰한 게 의미 있었다 |
findAndRankCandidates deprecated 표기만, 삭제 보류 | 삭제 보류 | 다음 머지에서 즉시 삭제. @deprecated 표기로 남기면 다음 작업자가 새 함수와 헷갈릴 위험이 더 크다. 모니터링 1주일 후 통째로 제거 |
| FB3(전체 활성)도 같은 풀에 흡수 | 흡수 안 함 | 흡수 안 함 결정 유지. FB3 발동 빈도가 < 1%라 추가 통합 이득이 적고, findActiveContents는 다른 서비스도 호출하는 공용 레퍼토리 메서드라 분리가 자연스럽다 |
| 인덱스 작업을 같은 머지에 묶기 | 분리했음 (다음 머지) | 분리한 결정 유지. prisma migrate가 같이 들어가면 본 머지의 회귀 폭이 커진다. 인덱스 추가는 회귀 폭이 좁아 별 머지로 두는 게 안전 |
[Profiling] 로그를 운영 모니터링 메트릭으로 승격 | 디버그 로그만 | 다음 마일스톤에서 OpenTelemetry로 승격. findCandidatesWithFallback total을 히스토그램 메트릭으로 노출하면 회귀 감지가 자동화된다 |
특히 1번 항목이 미묘하다. 페널티 전환과 단일 쿼리를 한 머지에 묶었다면 본 글 한 편으로 끝났을 텐데, 분리한 덕에 추천 분포 회귀를 1주일 관찰할 수 있었다. 추천 알고리즘 변경은 응답 형태가 같아도 점수 분포가 바뀌는 변경이라, 점수 분포가 안정됐다는 신호를 본 다음 메모리 풀로 옮기는 게 옳았다.
📌 핵심: 추천·정렬 알고리즘 최적화는 두 종류의 변경이 한 머지에 묶이면 회귀 분리가 어렵다 — 점수 분포(의미) 변경 vs 처리 경로(성능) 변경. 본 머지처럼 의미 변경을 먼저 깔고 1주일 분포 관찰 후 처리 경로 변경을 묶는 패턴이 한 머지의 범위를 좁힌다.
📋 정리 — 결정 요약 표
| 결정 | 본 머지의 처리 | 다음 머지의 빚 |
|---|---|---|
| 페널티 기반 순위 조정 (v2.1.5) | 1/26 별 머지로 선행 | — |
findByLevel 단일 쿼리로 풀 흡수 | 3차 최적화 본 머지 | — |
rankCandidatesFromPool 보조 함수 신설 | 3차 최적화 본 머지 | findAndRankCandidates 통째 삭제 |
[Profiling] 디버그 로그 11줄 | 3차 최적화 본 머지 | OpenTelemetry 메트릭 승격 |
FB3 별도 쿼리 유지 (findActiveContents) | 3차 최적화 본 머지에서 유지 결정 | — |
복합 인덱스 추가 ((bundleId, contentOrder), (studentId, contentId)) | 분리 | 다음 머지에서 측정 |
추천 후보 API의 응답 시간은 4,670ms → 2,340ms로 약 50% 줄었다. 폴백 쿼리 4~5회가 단일 쿼리 + 인메모리 필터링으로 바뀌었고, 같은 라운드에 들어간 권한 우회 픽스(이전 편)와 함께 본 머지 사이클의 회귀 차단 라인이 굳어졌다. 다음 편(devlog-52)에서는 같은 시점에 시작된 재화 시스템 — 코인과 EXP 도입의 첫 머지(Wallet API)를 정리한다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음