v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
전날 4,658줄짜리 DDD 문서를 박은 다음 날 저녁, 그 문서를 입력으로 받아 도메인 레이어 코드를 다시 박았다. 한 커밋에 1,682줄 추가. MetricRank TOP1~5와 V21_THRESHOLDS를 도메인 타입으로 박은 결정, ContentCandidateService의 후보 폴백 설계, 90% 이상도 복습 필수로 바꾼 ReviewModuleService 리팩토링, BundleCompleted 이벤트로 Aggregate 간 결합을 끊은 결정 — 다섯 개의 도메인 서비스가 같은 커밋에 들어간 이유와 각각의 설계 철학.
💡 Tip. 바쁜 현대인들을 위한 본문 요약
- 전날 밤(1/7) 4,658줄짜리 DDD 문서를 박았고, 그 다음 날 저녁(1/8 20:08) 그 문서를 입력으로 받아 코드 1,682줄을 한 커밋에 박았다. 커밋 ID는
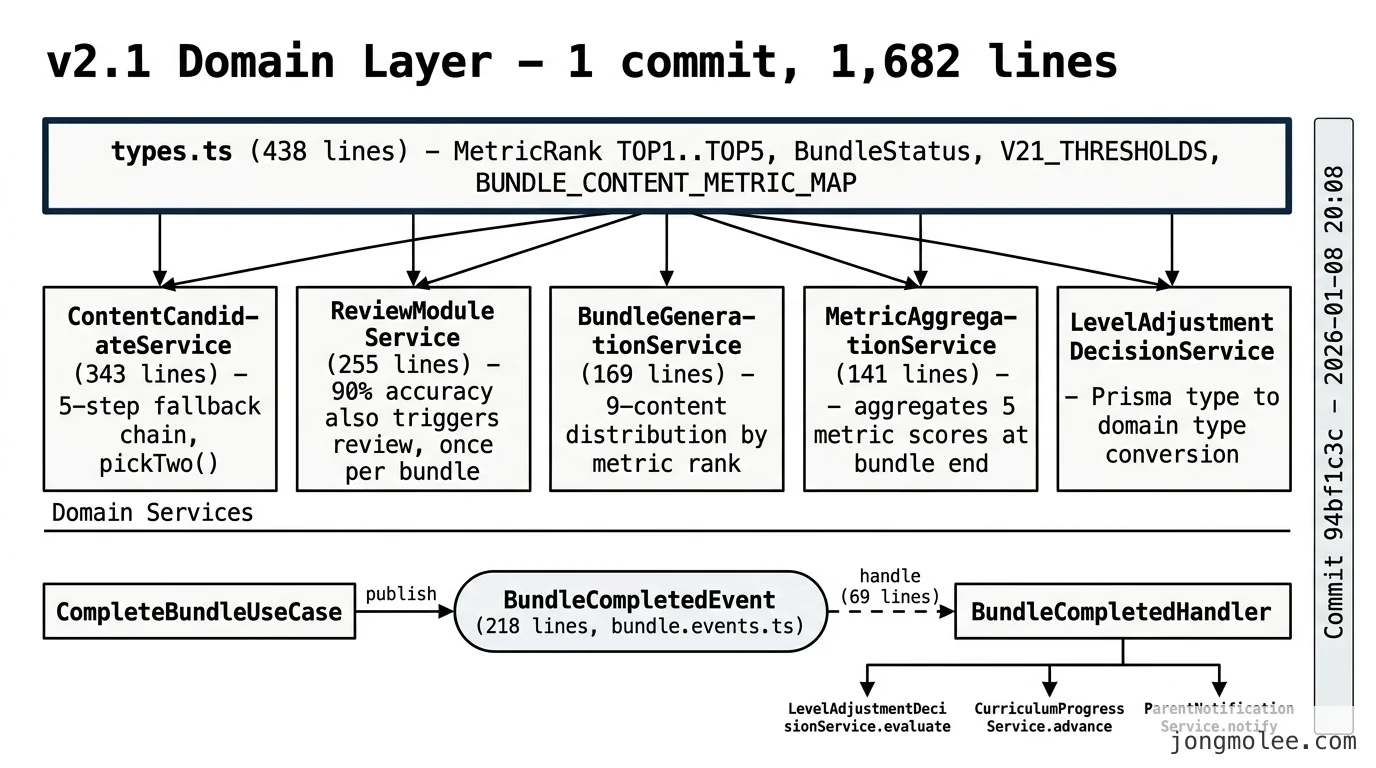
94bf1c3c, 메시지는feat: Domain Layer v2.1 구현 완료- 타입을 먼저 박았다.
types.ts438줄에MetricRankTOP1~5,BundleStatus,V21_THRESHOLDS,BUNDLE_CONTENT_METRIC_MAP같은 도메인 상수를 enum과 const로 고정. 도메인 레이어가 Prisma 타입을 직접 import하지 않도록 분리- 다섯 개 도메인 서비스가 같은 커밋에 들어갔다.
ContentCandidateService(343줄),ReviewModuleService(255줄),BundleGenerationService(169줄),MetricAggregationService(141줄), 그리고LevelAdjustmentDecisionService의 타입 전환- 이벤트 도입이 결정적이었다.
bundle.events.ts218줄과BundleCompletedHandler69줄을 한 번에 박아 Aggregate 사이의 직접 호출을 끊었다. v2.0까지는 서비스가 서비스를 호출했고, v2.1부터는 도메인 이벤트가 그 사이를 채운다- 앵글이 세 개 박혔다 — (1) 정확도 90% 이상도 복습은 필수다(레벨 하향 결정 분리), (2) 복습 모듈은 한 번만 발동한다(콘텐츠 3 완료 직후), (3)
INSUFFICIENT상태는 삭제하고 “완료 번들 0개 = POOR”로 단순화
🗺️ 이 편의 자리 — 문서를 입력으로 받아 코드를 다시 박는 단계
지난 편에서 24분 사이의 두 docs 커밋으로 v2.1 SSoT를 닫았다. 마스터 문서가 _v2.1.md로 갈아 끼워졌고, aggregates.md(1,090줄), repositories.md(911줄), bounded-contexts.md(750줄), domain-events.md(712줄)이 새로 깔렸다.
문제는 그 다음이었다. 문서는 v2.1인데 코드의 도메인 레이어는 여전히 v2.0이었다. v2.0 코드는 컴파일도 되고 테스트도 통과하는 상태였지만, v2.1 문서가 가리키는 — MetricRank TOP1~5, 사용자 콘텐츠 선택, 90% 이상도 복습 필수, PersonalRecord 삭제 — 같은 결정들은 코드 어디에도 반영되지 않았다.
1월 8일 저녁 8시 8분, 그 격차를 한 번에 좁히는 한 커밋이 들어갔다.
📌 핵심: DDD에서 “다음 단계는 타이핑이지 결정이 아니다”라는 말은 절반만 맞는다. 타입과 인터페이스는 문서가 결정해 주지만, 분리 기준 — 어떤 책임을 어떤 서비스에 둘지, 어디서 이벤트로 끊을지 — 은 코드를 박을 때 다시 한 번 결정된다.
커밋: 94bf1c3c
시각: 2026-01-08 20:08
제목: feat: Domain Layer v2.1 구현 완료
변경: 1,682줄 insert이 한 줄 요약 뒤에 다섯 개의 작은 결정이 숨어 있다. 이번 편은 그 다섯 개를 차례대로 풀어낸다.
🧱 결정 1 — 도메인 타입을 한 파일에 박는다 (types.ts 438줄)
도메인 레이어를 다시 박을 때 가장 먼저 한 일은 타입 한 곳에 모으기였다. 438줄짜리 types.ts 한 파일이 도메인 레이어의 정점에 앉는다.
왜 한 파일에 모으나
v2.0까지의 도메인 서비스는 Prisma가 생성한 타입을 그대로 import해서 썼다.
// ❌ v2.0 — Prisma 타입을 직접 도메인에서 사용
import { Prisma, BundleStatus } from '@prisma/client';
class BundleService {
computeStatus(bundle: Prisma.BundleGetPayload<...>): BundleStatus {
...
}
}문제는 두 가지다. 첫째, 도메인 레이어가 ORM에 종속된다. Prisma를 다른 ORM으로 바꾸면 도메인 코드가 통째로 흔들린다. 둘째, DB 스키마가 도메인 모델과 다른 진화 속도를 가질 때 둘이 충돌한다. 예컨대 v2.1 문서가 BundleStatus에 INSUFFICIENT를 삭제했지만, Prisma enum은 마이그레이션 전이라 여전히 INSUFFICIENT를 가지고 있는 상태가 한동안 이어진다.
// ✅ v2.1 — 도메인 타입을 별도 파일로 분리
// apps/api/src/domain/types.ts
export enum MetricRank {
TOP1 = 'TOP1',
TOP2 = 'TOP2',
TOP3 = 'TOP3',
TOP4 = 'TOP4',
TOP5 = 'TOP5',
}
export enum BundleStatus {
EXCELLENT = 'EXCELLENT',
NORMAL = 'NORMAL',
POOR = 'POOR',
// INSUFFICIENT 삭제됨 (v2.1) — 완료 번들 0개도 POOR로 통합
}
export const V21_THRESHOLDS = {
EXCELLENT_ACCURACY: 0.9,
POOR_ACCURACY: 0.7,
REVIEW_TRIGGER_AT_CONTENT_INDEX: 3,
CONSECUTIVE_DAYS_FOR_LEVEL_DOWN: 3,
CONSECUTIVE_DAYS_FOR_LEVEL_UP: 5,
} as const;
export const BUNDLE_CONTENT_METRIC_MAP: Record<MetricRank, number> = {
[MetricRank.TOP1]: 3,
[MetricRank.TOP2]: 2,
[MetricRank.TOP3]: 2,
[MetricRank.TOP4]: 1,
[MetricRank.TOP5]: 1,
};마지막 BUNDLE_CONTENT_METRIC_MAP이 핵심이다. 한 번들에 9개의 콘텐츠가 들어가는데, 그 9개를 5개의 인지 지표(TOP1~TOP5)에 어떻게 분배할지를 한 줄로 박아 둔 표다. TOP1 지표에 가장 약한 사용자에게 그 지표를 강화하는 콘텐츠를 3개 넣고, TOP5는 1개만 넣는다.
💡 인사이트: 도메인 상수를
as const로 박아 두면 IDE가 값까지 추적하기 시작한다.V21_THRESHOLDS.EXCELLENT_ACCURACY라고 쓴 자리에 마우스를 올리면0.9가 그대로 떠서, “이 임계값이 어디서 왔지?”를 grep할 필요가 없다.
도메인 타입과 Prisma 타입의 변환선
도메인 레이어를 ORM에서 분리하면 새 책임이 하나 생긴다 — 변환선을 어디에 두냐다. v2.1에서는 그 변환선을 Repository 인터페이스 자리에 박았다.
[Prisma] → [Repository 구현체] → [도메인 타입] → [도메인 서비스]
↑ 여기서 변환 한 번만 일어난다이 한 줄 그림이 도메인 레이어 1,682줄 전체의 뼈대다. types.ts는 그 뼈대의 상단을 차지하고, 다섯 도메인 서비스가 그 뼈대 위에서 각자의 책임을 풀어낸다.
🧮 결정 2 — ContentCandidateService 343줄, 후보 폴백을 도메인 책임으로
다섯 도메인 서비스 중 가장 큰 343줄짜리는 ContentCandidateService다. 이름 그대로 “콘텐츠 후보를 찾아 주는” 서비스인데, v2.1에서 이 서비스가 가지는 책임이 v2.0보다 훨씬 무거워졌다.
v2.0 → v2.1의 책임 변화
| 흐름 | v2.0 | v2.1 |
|---|---|---|
| 콘텐츠 선정 | 시스템이 자동 선택 → 1개 결정 | 시스템이 5개 후보 → 사용자가 2개 중 택1 |
| 폴백 | 후보 없으면 에러 | 5단계 폴백으로 항상 무언가 제시 |
| 입력 | 학생 ID + 번들 ID | 학생 ID + 번들 ID + 진행 인덱스(0~8) + 직전 결과 |
| 출력 | Content 한 개 | ContentCandidate[] (정확히 2개) |
자동 선택을 사용자 선택으로 바꾸는 결정이 도메인 서비스 343줄 안에 다 들어갔다. 핵심은 폴백 사슬이다.
5단계 폴백 사슬
// apps/api/src/domain/services/content-candidate.service.ts (발췌)
class ContentCandidateService {
async findCandidates(
studentId: StudentId,
bundleId: BundleId,
contentIndex: number,
): Promise<ContentCandidate[]> {
// [1차] 학생의 TOP1~5 지표 + 진행 인덱스에 매핑되는 후보
let candidates = await this.findByMetricMatch(studentId, contentIndex);
if (candidates.length >= 2) return this.pickTwo(candidates);
// [2차] 인접 지표(TOP±1) 후보 — 약점 지표가 부족할 때
candidates = await this.findByAdjacentMetric(studentId, contentIndex);
if (candidates.length >= 2) return this.pickTwo(candidates);
// [3차] 동일 레벨의 전체 콘텐츠
candidates = await this.findByLevel(studentId);
if (candidates.length >= 2) return this.pickTwo(candidates);
// [4차] 인접 레벨 (±1) 콘텐츠
candidates = await this.findByAdjacentLevel(studentId);
if (candidates.length >= 2) return this.pickTwo(candidates);
// [5차] 시스템 기본 콘텐츠 (운영팀이 정한 폴백 풀)
return this.fallbackPool();
}
}5단계 폴백을 도메인 서비스에 박아 둔 이유는 명확하다. “콘텐츠가 항상 2개 떠야 한다”는 것은 비즈니스 규칙이지 인프라 관심사가 아니다. UI에서 “후보 없음” 메시지를 띄우는 식으로 우회하면 사용자 경험이 무너지고, Repository 레이어에서 폴백을 처리하면 비즈니스 규칙이 데이터 접근 코드 안에 숨는다.
⚠️ 주의: 폴백이 5단계까지 늘어난 이유는 운영 첫 달의 데이터 부족을 가정했기 때문이다. 콘텐츠가 1,000개쯤 쌓이면 1차에서 거의 다 끝나지만, 첫 출시 직후엔 학생 한 명에 콘텐츠 200개도 안 되는 상태로 시작한다. 폴백을 빈약하게 만들면 처음 몇 주 동안 같은 학생에게 같은 콘텐츠가 반복 노출되는 문제가 그대로 터진다.
pickTwo의 작은 결정 — 다양성과 난이도의 균형
pickTwo 메서드는 한 줄짜리 함수가 아니다. 후보 풀에서 정확히 2개를 고를 때 하나는 학생의 약점 지표에 가깝게, 다른 하나는 한 단계 옆 지표로 골라 사용자에게 다양성의 인상을 주는 게 목적이다.
private pickTwo(candidates: ContentCandidate[]): ContentCandidate[] {
// 1번 슬롯: 약점 지표(TOP1) 우선
const slot1 = candidates.find(c => c.targetMetric === MetricRank.TOP1)
?? candidates[0];
// 2번 슬롯: 1번과 다른 지표
const slot2 = candidates.find(c =>
c.id !== slot1.id && c.targetMetric !== slot1.targetMetric
) ?? candidates.find(c => c.id !== slot1.id) ?? candidates[0];
return [slot1, slot2];
}두 줄로 끝나 보이지만, **“같은 지표 후보가 두 개 떠도 한 개는 다른 지표로 바꾼다”**는 규칙이 사용자 입장의 만족도를 크게 좌우한다. 같은 종류 두 개 중에서 고르라고 하면 “선택이 의미가 없다”는 느낌을 주고, 종류가 다르면 “내가 고른 결과로 다음이 달라진다”는 감각을 준다.
🔁 결정 3 — ReviewModuleService 255줄, 구 LevelingModule을 비즈니스 규칙대로 다시 짠다
v2.0 시절 LevelingModule이라고 부르던 모듈이 v2.1에서 ReviewModuleService로 이름까지 바꿨다. 단순한 리네이밍이 아니라 발동 조건이 통째로 바뀌었기 때문이다.
v2.0 → v2.1의 발동 조건
| 발동 조건 | v2.0 (LevelingModule) | v2.1 (ReviewModuleService) |
|---|---|---|
| 정확도 70% 미만 | 복습 모듈 발동 | 복습 모듈 발동 |
| 정확도 70~89% | 복습 없음 | 복습 없음 |
| 정확도 90% 이상 | 레벨 업 | 복습 모듈 발동(필수) + 레벨업 후보 |
| 발동 횟수 | 매 콘텐츠마다 가능 | 한 번들에 1회만 |
| 발동 시점 | 즉시 | 콘텐츠 3 완료 직후 |
가장 큰 결정은 가운데 줄이다 — “정확도 90% 이상도 복습은 필수”.
// apps/api/src/domain/services/review-module.service.ts (발췌)
class ReviewModuleService {
shouldTrigger(
bundleProgress: BundleProgress,
lastAttempt: ContentAttempt,
): ReviewTriggerDecision {
// 한 번들에 한 번만
if (bundleProgress.reviewModuleApplied) {
return { trigger: false, reason: 'ALREADY_APPLIED' };
}
// 콘텐츠 3 완료 직후만
if (bundleProgress.contentIndex !== V21_THRESHOLDS.REVIEW_TRIGGER_AT_CONTENT_INDEX) {
return { trigger: false, reason: 'WRONG_INDEX' };
}
// 정확도가 0.7 미만이거나 0.9 이상이면 복습
const acc = lastAttempt.accuracy;
if (acc < V21_THRESHOLDS.POOR_ACCURACY) {
return { trigger: true, reason: 'POOR_ACCURACY' };
}
if (acc >= V21_THRESHOLDS.EXCELLENT_ACCURACY) {
return { trigger: true, reason: 'EXCELLENT_ACCURACY' };
}
return { trigger: false, reason: 'IN_RANGE' };
}
}세 단어로 요약하면 **“양 끝은 둘 다 복습”**이다. 너무 못 풀어도 복습, 너무 잘 풀어도 복습. 직관과 어긋나는 이 결정의 근거는 **“잘 푼 게 운인지 실력인지를 한 번 더 확인해야 레벨업이 안전하다”**는 도메인 전문가의 요구다.
레벨업 결정과 복습 발동의 분리
이 부분이 v2.0 코드와 v2.1 코드의 가장 큰 구조적 차이다.
v2.0: [LevelingModule] → 복습 + 레벨 결정을 한 모듈에서 묶음
v2.1: [ReviewModuleService] 복습 발동 여부만 판단
[LevelAdjustmentDecisionService] 레벨 결정만 판단
두 서비스가 BundleCompleted 이벤트를 통해 느슨하게 연결한 모듈이 두 책임을 가지면 변경이 전파된다. v2.0 시절 “복습 트리거 조건”을 한 줄 바꾸면 레벨 결정 로직까지 회귀 테스트를 다시 돌려야 했다. v2.1에서 두 서비스로 쪼갠 뒤로는 ReviewModuleService 단위 테스트와 LevelAdjustmentDecisionService 단위 테스트가 따로 살아 있다.
📌 핵심: 도메인 서비스의 분리 기준은 *“같이 자주 바뀌는가”*다. 같이 자주 바뀌면 한 서비스에 두고, 따로 자주 바뀌면 갈라낸다. 복습 트리거와 레벨 결정은 비즈니스 규칙의 진화 속도가 다르다는 게 분리의 결정적 근거였다.
📦 결정 4 — BundleGenerationService 169줄과 MetricAggregationService 141줄을 같은 위계에 둔다
두 서비스의 책임은 다음과 같다.
| 서비스 | 줄 수 | 책임 |
|---|---|---|
BundleGenerationService | 169 | 학생의 다음 번들을 만든다 (콘텐츠 9개 구성) |
MetricAggregationService | 141 | 한 번들이 끝났을 때 5개 지표 점수를 집계한다 |
두 서비스를 같은 위계(domain/services/)에 두는 결정에는 대칭성에 대한 미적 판단이 들어간다. BundleGenerationService가 번들의 시작을 책임지면, MetricAggregationService는 번들의 끝을 책임진다. 한 사이클의 진입과 출구를 같은 디렉터리 같은 위계에 두면 코드를 읽는 사람이 흐름을 추적하기 쉽다.
BundleGenerationService.generate()의 한 줄 책임
class BundleGenerationService {
async generate(studentId: StudentId): Promise<Bundle> {
const student = await this.studentRepo.findById(studentId);
const ranking = student.getMetricRanking(); // TOP1~TOP5
// BUNDLE_CONTENT_METRIC_MAP: { TOP1: 3, TOP2: 2, TOP3: 2, TOP4: 1, TOP5: 1 }
const distribution = BUNDLE_CONTENT_METRIC_MAP;
const contents: BundleContent[] = [];
for (const [rank, count] of Object.entries(distribution)) {
const metric = ranking.get(rank as MetricRank);
const items = await this.contentRepo.findByMetricAndLevel(metric, student.currentLevelId, count);
contents.push(...items.map(c => BundleContent.from(c, metric)));
}
return Bundle.create(studentId, contents);
}
}이 한 메서드 안에 **“번들은 9개의 콘텐츠로 이뤄지고, TOP1 지표 콘텐츠가 가장 많이 들어간다”**는 비즈니스 규칙이 그대로 박혀 있다. 다른 곳에 같은 규칙이 중복돼 있으면 안 된다는 것이 이 서비스를 한 파일로 박은 이유다.
MetricAggregationService의 위치 — 도메인 vs 애플리케이션
처음에는 MetricAggregationService를 애플리케이션 레이어에 두려 했다. 집계는 “번들이 끝났을 때 누가 시킬지”의 문제고, 그건 유즈케이스의 책임처럼 보였기 때문이다.
첫 번째 시도(잘못된 자리):
- application/use-cases/complete-bundle.usecase.ts
└ MetricAggregationService 직접 호출문제는 집계 알고리즘 자체가 도메인 규칙이라는 점이었다. 어떤 지표 점수를 어떻게 가중평균할지, 5번의 시도 중 마지막 시도만 반영할지 평균을 낼지 — 이 결정이 통째로 도메인의 핵심 비즈니스 규칙이다. 애플리케이션 레이어에 두면 같은 규칙이 다른 유즈케이스에서 재구현될 위험이 있다.
v2.1의 자리(올바른 자리):
- domain/services/metric-aggregation.service.ts (141줄)
└ 알고리즘 자체는 여기서 한 번만 구현
- application/use-cases/complete-bundle.usecase.ts
└ MetricAggregationService.aggregate(...) 호출만 담당💡 인사이트: **“이 코드를 다른 유즈케이스에서도 재사용할 가능성이 있나?”**라는 질문이 도메인 서비스 vs 애플리케이션 서비스의 위치 결정에 가장 잘 듣는다. 답이 “있다”면 도메인, “이 한 유즈케이스 전용”이면 애플리케이션이다. 집계 알고리즘은 학부모 리포트 / 학생 대시보드 / 운영자 통계 모두에서 재사용될 가능성이 높았기 때문에 도메인으로 갔다.
📡 결정 5 — BundleCompleted 이벤트로 Aggregate 사이를 끊는다
이 한 커밋에서 가장 구조적으로 큰 변화는 이벤트 도입이다. bundle.events.ts 218줄과 BundleCompletedHandler 69줄이 같이 박혔다.
v2.0의 호출 사슬
// ❌ v2.0 — 서비스가 서비스를 직접 호출
class CompleteBundleUseCase {
async execute(bundleId: BundleId) {
const bundle = await this.bundleService.complete(bundleId);
// 한 유즈케이스에서 4개 서비스 직접 호출
await this.metricAggregationService.aggregate(bundle);
await this.levelAdjustmentService.evaluate(bundle.studentId);
await this.curriculumProgressService.advance(bundle.studentId);
await this.notificationService.notifyParent(bundle.studentId);
}
}번들 완료 한 번에 후속 처리 4개가 직접 호출된다. 새 후속 처리가 추가될 때마다 이 유즈케이스가 길어지고, 한 호출이 실패하면 트랜잭션 경계가 흔들린다. 무엇보다 유즈케이스가 후속 처리들의 존재를 알아야 한다는 결합이 도메인 분리 원칙과 어긋났다.
v2.1의 이벤트 분리
// apps/api/src/events/types/bundle.events.ts (발췌)
export class BundleCompletedEvent {
constructor(
public readonly bundleId: BundleId,
public readonly studentId: StudentId,
public readonly status: BundleStatus,
public readonly completedAt: Date,
public readonly aggregatedMetrics: StudentMetricScore[],
) {}
}
// apps/api/src/events/handlers/bundle-completed.handler.ts (발췌)
@EventsHandler(BundleCompletedEvent)
export class BundleCompletedHandler {
constructor(
private readonly levelAdjustment: LevelAdjustmentDecisionService,
private readonly curriculumProgress: CurriculumProgressService,
private readonly parentNotification: ParentNotificationService,
) {}
async handle(event: BundleCompletedEvent) {
await Promise.all([
this.levelAdjustment.evaluate(event.studentId),
this.curriculumProgress.advance(event.studentId),
this.parentNotification.notify(event.studentId, event.status),
]);
}
}이렇게 자르고 나면 유즈케이스는 짧아진다.
// ✅ v2.1
class CompleteBundleUseCase {
async execute(bundleId: BundleId) {
const bundle = await this.bundleService.complete(bundleId);
const metrics = await this.metricAggregationService.aggregate(bundle);
this.eventBus.publish(
new BundleCompletedEvent(bundle.id, bundle.studentId, bundle.status, new Date(), metrics)
);
}
}후속 처리 4개가 1개 이벤트로 줄었다. 새 후속 처리가 생기면 새 핸들러 하나만 추가하면 되고, 유즈케이스 코드는 전혀 안 바뀐다.
이벤트로 끊으면 좋은 점과 잃는 점
| 항목 | 이벤트 도입 전 | 이벤트 도입 후 |
|---|---|---|
| 결합도 | 유즈케이스 → 4개 서비스 직접 의존 | 유즈케이스 → 이벤트만 발행, 핸들러는 따로 등록 |
| 추적성 | 호출 사슬을 IDE에서 따라가기 쉬움 | 핸들러 등록 위치를 별도로 알아야 함 |
| 트랜잭션 | 한 트랜잭션에 묶을지 명확함 | 핸들러가 비동기일 때 경계가 흐려짐 |
| 새 후속 추가 | 유즈케이스 수정 필요 | 핸들러 추가만 하면 됨 |
이 표의 가운데 두 줄(추적성, 트랜잭션)이 이벤트 도입의 비용이다. 도메인 이벤트로 끊으면 IDE에서 “이 함수가 어디서 호출되는지”를 추적하기가 어려워지고, 실패 시 롤백 경계가 흐려진다. 이걸 알면서도 끊은 이유는, 후속 처리가 5개를 넘어가는 시점부터는 유즈케이스가 길어지는 비용이 추적성 손실보다 크다고 판단했기 때문이다.
🔍 단서: 이벤트 도입은 “후속 처리가 늘어날 것이 거의 확실할 때”만 한다. 후속이 1~2개에 머물 거라고 예상되면 직접 호출이 더 명료하다. 우리 도메인은 이미 4개에 달했고, 학습 분석 / 게이미피케이션 / 리포트 같은 후속이 더 붙을 게 분명했기 때문에 끊는 게 옳았다.
🛡️ 다섯 결정의 공통 원칙 — 한 커밋 안에 묶은 이유
다섯 도메인 서비스를 한 커밋에 박은 결정도 의도적이었다.
원칙 1 — 도메인 레이어는 “동시에 한 버전이어야 한다”
도메인 레이어를 잘게 쪼갠 커밋들로 박으면 중간 어딘가의 커밋이 반쯤 v2.0, 반쯤 v2.1인 상태가 된다. 그 상태에서 동료가 PR을 가지고 와서 합치면 충돌이 입체적으로 일어난다. 한 커밋에 전부 박으면 어떤 시점이든 도메인 레이어 전체가 한 버전이라는 불변량이 지켜진다.
원칙 2 — types.ts가 다른 모든 파일의 입력이라 분리할 수 없다
MetricRank, BundleStatus, V21_THRESHOLDS를 별도 커밋에 먼저 박으면, 다음 커밋의 도메인 서비스들이 그 타입을 참조하지 않은 채 컴파일이 되는 짧은 시간이 생긴다. 그 시간에 빌드를 돌리면 v2.1 타입은 있지만 그걸 쓰는 코드는 없는 상태가 된다. 같이 박는 게 깔끔하다.
원칙 3 — 이벤트 도입은 “발행자 + 구독자”가 같이 있어야 의미가 있다
BundleCompletedEvent만 따로 박으면 발행할 사람도 구독할 사람도 없는 고아 클래스가 된다. BundleCompletedHandler만 따로 박으면 들어올 이벤트 정의가 없어 컴파일도 안 된다. 둘은 한 단위다.
원칙 4 — 1,682줄짜리 PR은 문서가 정확히 박혔을 때만 가능하다
같은 1,682줄짜리 커밋이 지난 편의 4,658줄짜리 DDD 문서 없이 들어왔다면, 코드 리뷰가 불가능했을 것이다. “이게 왜 이 모양이지?”라는 질문 하나하나에 문서를 가리키며 답할 수 있어야 큰 커밋이 정당화된다. 1,682줄 / 4,658줄의 비율이 1:2.77이라는 점도 의미가 있다 — 코드 한 줄 뒤에 문서 두 줄이 받쳐 준다는 뜻이다.
원칙 5 — LevelAdjustmentDecisionService의 타입 전환이 “마지막 한 줄”이다
이 서비스 자체는 v2.0에도 있었다. v2.1에서 변한 건 입력 타입이 Prisma 타입에서 도메인 타입으로 바뀐 것 한 가지다.
// ❌ v2.0
async evaluate(student: Prisma.StudentGetPayload<{ include: {...} }>): Promise<LevelDecision>
// ✅ v2.1
async evaluate(studentId: StudentId): Promise<LevelDecision>
// ↑
// Prisma 타입을 받지 않고 ID만 받아서, Repository로 조회작아 보이지만 도메인 레이어가 ORM을 import하지 않는다는 원칙을 마지막 한 줄에서 박는 변경이다. 이 한 줄이 빠져 있으면 위의 다섯 결정이 다 무너진다. 그래서 같은 커밋에 같이 들어갔다.
📋 정리 — 핵심 요약
도메인 레이어 1,682줄을 한 커밋에 박은 결정은, 사실 문서 → 타입 → 서비스 → 이벤트 순으로 뼈대를 한 번에 세운 의식이었다.
| 결정 | 안티패턴 | v2.1 권장 패턴 |
|---|---|---|
| 도메인 타입 위치 | ❌ Prisma 타입을 도메인에서 직접 import | ✅ types.ts 한 곳에 enum/const 박고 Repository에서 변환 |
| 콘텐츠 후보 | ❌ “후보 없음” 시 에러 / UI 우회 | ✅ 5단계 폴백을 도메인 책임으로 박음 |
| 복습 모듈 | ❌ 복습 + 레벨 결정 한 모듈에 묶음 | ✅ 두 책임을 분리, 도메인 이벤트로 연결 |
| 집계 서비스 위치 | ❌ 애플리케이션 레이어 | ✅ 도메인 레이어 (재사용 가능성 + 알고리즘이 도메인 규칙) |
| 후속 처리 | ❌ 유즈케이스가 4개 서비스 직접 호출 | ✅ BundleCompleted 이벤트로 끊고 핸들러가 분담 |
| 커밋 단위 | ❌ 도메인 서비스별로 잘게 쪼갬 | ✅ 한 커밋에 묶어 도메인 레이어를 원자적 한 버전으로 박음 |
다음 편 — Repository + Application 재작성에서는 이 도메인 레이어 위에 Repository 구현체와 Application 유즈케이스를 다시 박는 이야기로 넘어간다. 도메인이 ORM에서 깨끗이 분리됐다면, 이제 분리된 자리를 어떻게 다시 잇느냐가 다음 단계의 책임이다.
📚 NestJS + Refine 풀스택 트러블슈팅 시리즈 (63편)
- 1. 왜 NestJS + Prisma를 선택했나 — B2B SaaS 백엔드 기술 선택기
- 2. 도메인 모델링 첫날 — B2B SaaS의 핵심 엔티티 정의하기
- 3. 27개 테이블의 탄생 — Prisma 스키마 설계기
- 4. 권한 매트릭스 — Admin/운영자/사용자 3역할 설계
- 5. BigInt PK에서 Int PK로 — 첫 번째 스키마 리팩토링
- 6. Seed 데이터의 함정 — FK 삭제 순서 삽질기
- 7. DDD를 도입하기로 했다 — Repository/Domain/Application 3계층
- 8. 인터페이스 구현체로 바꾸는 날 — NestJS DI와 TypeScript의 간극
- 9. 단위 테스트 인프라 구축 — Jest 설정부터 Mock까지
- 10. E2E 테스트와 Cloud SQL의 고난 — 4/8 passing에서 8/8까지
- 11. REST API 첫 구현 — 6개 Controller, 21개 엔드포인트 완성
- 12. v1.0 완성, 그리고 갈아엎기로 결심한 날
- 13. 번들 구조를 통째로 바꿔야 했던 이유
- 14. Phase 1 문서 정비 — Use Case를 번들 기반으로 다시 쓰다
- 15. Phase 2 스키마 마이그레이션 — 데이터 안 날리고 구조 바꾸기
- 16. Phase 3-1·3-2 — Repository와 Domain 서비스로 36개 빌드 에러 잡기
- 17. Phase 3-3·3-4·3-5 — Application부터 Module까지, v2.0 마이그레이션 닫는 날
- 18. 코드를 박은 다음 날 — 4,658줄 DDD 문서를 24분 사이에 다시 쓴 하루
- 19. v2.1 Domain Layer — 도메인 서비스 1,682줄을 한 커밋에 박은 날의 설계 철학
- 20. v3.0 Application Layer 재작성 — 도메인 서비스 위에 얇은 막을 한 Phase에 박은 날
- 21. 갈아엎고 80일 — v2.0 마이그레이션 8편 메타 회고
- 22. 1인 다역으로 5일 만에 90% — Admin Portal MVP를 끌어올린 토글 한 줄
- 23. Mock에선 되던 게 REST에선 안 됐다 — 응답 포맷 한 칸 차이가 만든 하루
- 24. CORS는 됐다 — PATCH만 빼고. allowedHeaders 한 줄과 Vite 프록시의 소문자 메서드
- 25. 멀티테넌트 누수 — tenantId 3계층 강제
- 26. Prisma 정책 싱글톤 — zod superRefine 임계값 가드
- 27. 멀티테넌트 쓰기 가드 — body.tenantId 차단과 집계 일관성
- 28. 두 번째 점검은 합류 지점이었다 — Admin Portal 2차에서 한 사이클에 잡힌 FE-BE 연동 버그 11건
- 29. Prisma 그래프 스키마 — 선형 레벨을 DAG로 옮긴 4가지 결정
- 30. 교육과정 구조 리팩토링 — 3필드 분리와 폴백 결정기
- 31. 배치고사 MVP — 자동 레벨 배치를 걷어내고 5지표 측정만 남기다
- 32. JWT Guard 적용 — request.user undefined부터 jwt malformed까지
- 33. 디버깅용 운영 API 7개 — Unity 만료 테스트 30분 대기를 0초로
- 34. NestJS Swagger 일괄 적용 — 35개 컨트롤러 + DTO 22개
- 35. Unity ↔ 웹 PostMessage 브릿지 설계기
- 36. Vuplex 브릿지 초기화 타이밍 — 첫 메시지가 증발한 이유
- 37. 콘텐츠 브릿지 10종 통합 완료 — 같은 규격으로 묶기
- 38. 지표 누계 시스템 — TOP5 순위를 INSERT 전용 스냅샷으로 굳히기
- 39. 킥오프 배치 첫 구현 — 매시 전체 EXPIRED 사고와 Winston 도입
- 40. 혼자 여러 역할로 QA 1차 — 브랜치 미동기화와 잔존 토큰의 함정
- 41. 타이머가 NaN:NaN으로 떴다 — Bundle API 응답 누락 필드와 비어 있는 콘텐츠 후보
- 42. 1인 개발 QA 5라운드 — 타이머·시드·스키마로 옮긴 버그들
- 43. Unity Lobby + 배치고사 씬 통합 — 두 클라이언트가 같은 회원을 보는 첫 빌드
- 44. 배치고사 MVP 후속 — 명세를 코드로 옮기고 레거시 571줄을 일괄 삭제하다
- 45. Problem 종속 끊기 — 1,891개 마이그레이션과 단위 테스트 38건
- 46. NestJS 권한 가드 — 목록은 막고 상세는 뚫린 날
- 47. 콘텐츠 후보 선택 3차 최적화 — 단일 쿼리로 옮기기
- 48. 재화 시스템 첫 머지 — 코인 지갑과 거래 원장(Wallet API)
- 49. 회원 레포트 5탭 API 설계 — 인사이트 3파트 구조
- 50. 보호자 외부 뷰어 대시보드 — 모바일 앱·초대 토큰 회원가입
- 51. 외부 뷰어 리포트 v1→v2 토큰 전환 — 가장 길었던 하루
- 52. 외부 뷰어 리포트 인사이트 — 활동 데이터를 자연어로 바꾸기
- 53. Framer Motion whileInView — 일부 카드만 안 뜨던 날
- 54. 외부 뷰어 리포트 4탭 N+1 — 14초 응답을 2초로
- 55. Cloud SQL 리전 트랩 — US→Taiwan 71% 트러블슈팅
- 56. QR 배치고사 + Firebase Hosting 멀티 사이트 배포
- 57. 1,974줄 풀 백업 — 1인 개발에서 상태 관리하는 법
- 58. 주간 출석 KST 타임존 — 월요일이 사라진 트러블슈팅
- 59. 연락처 포맷 통일 — 저장은 숫자만, 표시는 하이픈
- 60. react-hook-form + Zod 폼 표준 정착기
- 61. Soft Delete 구현 — deletedAt 한 컬럼이 닿은 27곳의 설계
- 62. 교육과정 자동 승급의 늪 — 도메인 버그 3 건 트러블슈팅
- 63. 교육과정 도메인 BE 완성과 같은 날 핫픽스 7 건 — NestJS @Cron 2 중 실행 묶음