AI 4명을 부렸는데 결국 나만 바빴다 — 수동 오케스트레이션의 한계
📚 Claude Code 팀 에이전트 실전기 시리즈 (3편)
Claude Code 세션 4개를 PM/BE/FE/QA로 나눠 3개월간 운영한 경험. session-sync.md로 에이전트 간 통신을 구현했지만, 사람이 중계하는 구조의 한계를 깨달은 이야기.
💡 Tip. 바쁜 분들을 위한 본문 요약
- Claude Code 세션 4개를 PM/BE/FE/QA로 나눠서 3개월간 운영했다
- session-sync.md라는 공유 문서로 에이전트 간 통신을 구현 → 변경 명세서 66개 산출
- 메시지를 쓰고 읽는 건 에이전트, 사람은 sync 문서의 IO를 트리거하는 중계자
- 중계 과정에서 optional 필드 하나가 증발 → 런타임 에러로 한 시간 날림
- 결론: AI가 몇 명이든, 중계가 사람이면 처리량은 사람 한계에 묶인다
터미널 4개, 지시와 검수의 무한루프

모노레포 하나에 백엔드(NestJS), 프론트 3개(React), Unity 클라이언트가 담긴 B2B SaaS를 만들고 있었다. 혼자서. 코드 4만 줄, 도메인 서비스 21개, Prisma 스키마만 수백 줄 — 1인 개발치고는 꽤 큰 프로젝트였다.
Claude Code를 도입하면서 세션을 역할별로 나눴다. Git Worktree로 독립 작업 디렉토리를 주고, .claude/skills/role-* 파일로 각 세션에 역할을 부여했다. PM이 지시하고, BE가 API를 만들고, FE가 UI를 입히는 구조.
project-root/ ← main (PM 세션)
├── worktree-be/ ← BE 세션 (git worktree)
├── worktree-fe/ ← FE 세션 (git worktree)
├── worktree-qa/ ← QA 세션 (git worktree)
├── session-sync.md ← 공유 문서 (Git 외부)
└── .claude/
└── skills/
├── role-pm.md
├── role-be.md
├── role-fe.md
└── role-qa.md터미널 4개에 각 세션을 띄워놓고, AI 4명이 동시에 일하는 그림을 그렸다. tmux 4분할 화면에서 각 세션의 진행 상황을 실시간으로 볼 수 있었다. CLAUDE.md에 프로젝트 전체 맥락을 넣어두고, 각 세션이 자기 role 파일과 CLAUDE.md를 동시에 참조하면서 작업하게 했다.
4명은 서로의 존재를 알고 있었다. .claude/skills/role-* 파일에 다른 세션의 역할이 명시되어 있으니까. PM 에이전트는 BE에게 뭘 요청해야 하는지 알고, FE 에이전트는 BE가 만든 API를 연동해야 한다는 걸 안다. QA 에이전트는 BE와 FE의 산출물을 검수하고, 빌드와 타입 체크를 돌리는 게이트키퍼 역할이다.
📌 핵심:
CLAUDE.md가 SSoT(Single Source of Truth) 역할을 한다. 프로젝트의 아키텍처, 도메인 규칙, 코딩 컨벤션이 여기 들어가고, 모든 세션이 이걸 읽고 시작한다. 세션별 role 파일은 “너는 BE야”라는 역할 경계만 정의한다.
문제는 이 4명이 직접 소통할 수 없다는 거다. Claude Code 세션은 독립적이다. 같은 레포를 보고 있어도 세션 A에서 한 대화를 세션 B가 알 방법이 없다. 서로의 역할은 알지만, 대화는 항상 사람의 중계를 통해야 했다.
그래서 세션 간 통신을 직접 만들었다.
session-sync.md — 에이전트가 쓰고 읽는, 사람이 중계하는 문서
프로젝트 상위 폴더에 session-sync.md를 만들었다. Git 외부에 두고, 모든 세션이 읽고 쓰는 공유 문서다.
핵심 구조는 이렇다: 메시지를 작성하고 읽는 건 에이전트들이다. PM 에이전트가 지시를 쓰고, FE 에이전트가 결과를 쓰고, 다른 에이전트가 그걸 읽는다. 사람인 내가 하는 건 sync 문서의 IO를 트리거하는 것이다 — 각 터미널에서 “session-sync에 써”, “session-sync 읽어”라고 에이전트에게 지시하는 역할.
실제로 이런 형태의 메시지가 오갔다:
## [PM → FE] 2026-03-26 — 필터 + 테이블 정렬
### BE (배포 완료)
신규 API: GET /admin/monitoring/groups → [{ id, name, count }]
기존 API 변경: 모든 집계 API에 groupId, 목록 API에 sortField + sortOrder 추가.
### FE 작업
#### 1. 필터 드롭다운
- 페이지 상단에 Select — "전체" (기본) + 그룹별 선택
- 선택 시 모든 탭에 groupId 전달
#### 2. 테이블 헤더 정렬
- 클릭 시 asc → desc → 기본 토글
- sortField + sortOrder API 전달
- 정렬 가능 필드: name, status, accuracy, elapsedMinutes...## [FE → PM] 2026-03-26 — 필터 + 테이블 정렬 완료
### 커밋
`7847f27` feat(admin): 필터 + 정렬
### 변경 파일 (5파일)
| # | 파일 | 변경 |
|---|------|------|
| 1 | components/sortable-header.tsx | 신규 — 정렬 가능 헤더 (asc→desc→기본) |
| 2 | index.tsx | 필터 Select + state + 탭에 props 전달 |
| 3 | tabs/data-tab.tsx | groupId + sort API 전달 + SortableHeader |
| 4 | tabs/status-tab.tsx | 동일 |
| 5 | tabs/stats-tab.tsx | 동일 |
### 빌드
tsc --noEmit ✅에이전트들이 작성하는 보고서가 이 수준이다. 커밋 해시, 변경 파일, 빌드 결과까지. 사람이 쓰는 것보다 정형화되어 있다.
사람이 중계하는 이유
왜 에이전트끼리 직접 읽고 쓰게 안 했을까? 할 수는 있다. 하지만 의도적으로 사람을 중계자로 뒀다.
처음에는 비즈니스 로직이 복잡해서 에이전트를 신뢰하기 어려웠다. PM이 작성한 지시가 비즈니스 맥락에 맞는지, BE가 구현한 로직이 도메인 규칙을 제대로 반영했는지 — 사람이 직접 확인하고 싶었다.
그런데 3개월간 검수하면서 알게 됐다. 잘게 나뉜 역할에서는 에이전트가 꽤 정확하다. “모니터링 API에 그룹 필터를 추가해줘”처럼 구체적인 지시를 주면, BE 에이전트는 알아서 적절한 엔드포인트를 만들고 테이블을 조인하고 빌드까지 확인한다. 의심했던 것만큼 자주 틀리지 않았다.
결국 사람이 중계자로 남은 건 신뢰 문제가 아니라 구조적 한계 때문이었다:
- 인터셉트: PM 에이전트가 BE에게 보낼 지시를 작성하면, 내가 중간에서 확인할 수 있다. “이 방향 아닌데?” 하고 회수해서 다시 쓰게 하거나, 스펙을 보강해서 전달하거나.
- 품질 게이트: 매 단계에서 에이전트의 아웃풋을 검수하고 조율할 수 있다. BE가 올린 커밋을 확인하고, FE에게 전달하기 전에 빌드를 돌려보거나.
대신, 모든 수발신이 사람의 트리거를 필요로 한다. BE가 작업을 끝내고 sync 문서에 보고를 써도, 내가 FE 터미널에 가서 “sync 읽어”라고 말하기 전까지 FE는 모른다.
2026년 1월부터 4월까지, 3개월간 이 구조로 변경 명세서 66개를 찍어냈다. CLAUDE.md를 SSoT로 관리하면서 전체 방향을 잡고, 각 세션이 자기 역할에 집중하는 파이프라인. 꽤 잘 동작했다.
그러다 어느 날 깨달았다.
그날의 삽질: 타입 한 줄이 증발했다

BE 에이전트가 API 응답 타입을 변경했다. 기존에 배열을 직접 반환하던 것을 래핑 객체로 바꾸면서, sync 문서에 변경 내역을 상세하게 보고했다. PM 에이전트가 그걸 읽고 FE에게 전달할 지시를 작성했다.
나는 PM 에이전트가 쓴 지시를 훑어보고, FE 터미널에서 “sync 읽어”를 트리거했다.
FE가 작업을 끝내고 빌드를 돌렸다. tsc --noEmit 통과. 문제없어 보였다.
그런데 런타임에서 터졌다.
TypeError: Cannot read properties of undefined (reading 'map')
at DashboardStats (dashboard-stats.tsx:47:22)
at renderWithHooks (react-dom.development.js:14985:18)
at mountIndeterminateComponent (react-dom.development.js:17811:13)BE가 추가한 optional 필드 하나가 PM→FE 전달 과정에서 빠졌다. BE의 원본 보고에는 있었다. PM 에이전트가 FE 지시를 작성하면서 200줄짜리 변경 내역 중 그 필드를 누락했고, 내가 인터셉트 단계에서 그걸 잡지 못했다.
원인을 찾는 데 한 시간, 수정 3분. BE 보고를 다시 읽어보니 거기엔 분명하게 적혀 있었다.
## [BE → PM] 변경 내역 (원본)
- data: T[] → { items: T[], total: number, metadata?: { groupName: string } }
- ⚠️ metadata는 groupId 쿼리 시에만 포함 (optional)PM 에이전트가 FE용으로 재작성하면서 metadata 필드를 생략했다. 200줄짜리 변경 내역 중 optional 필드 하나. 내가 인터셉트 단계에서 확인했지만, API 변경 자체가 아니라 UI 작업 지시에 집중하다 보니 응답 스키마의 디테일은 흘려 넘겼다.
⚠️ 주의: 이게 수동 오케스트레이션의 구조적 취약점이다. 사람이 중계자일 때, 정보의 완전성은 사람의 집중력에 의존한다. 66번의 중계 중 65번이 정확해도, 1번의 누락이 한 시간짜리 디버깅으로 돌아온다.
AI 4명이 일하는데, 정보가 증발한 건 중계 과정이었다.
사람이 허브인 구조는 스케일 안 한다

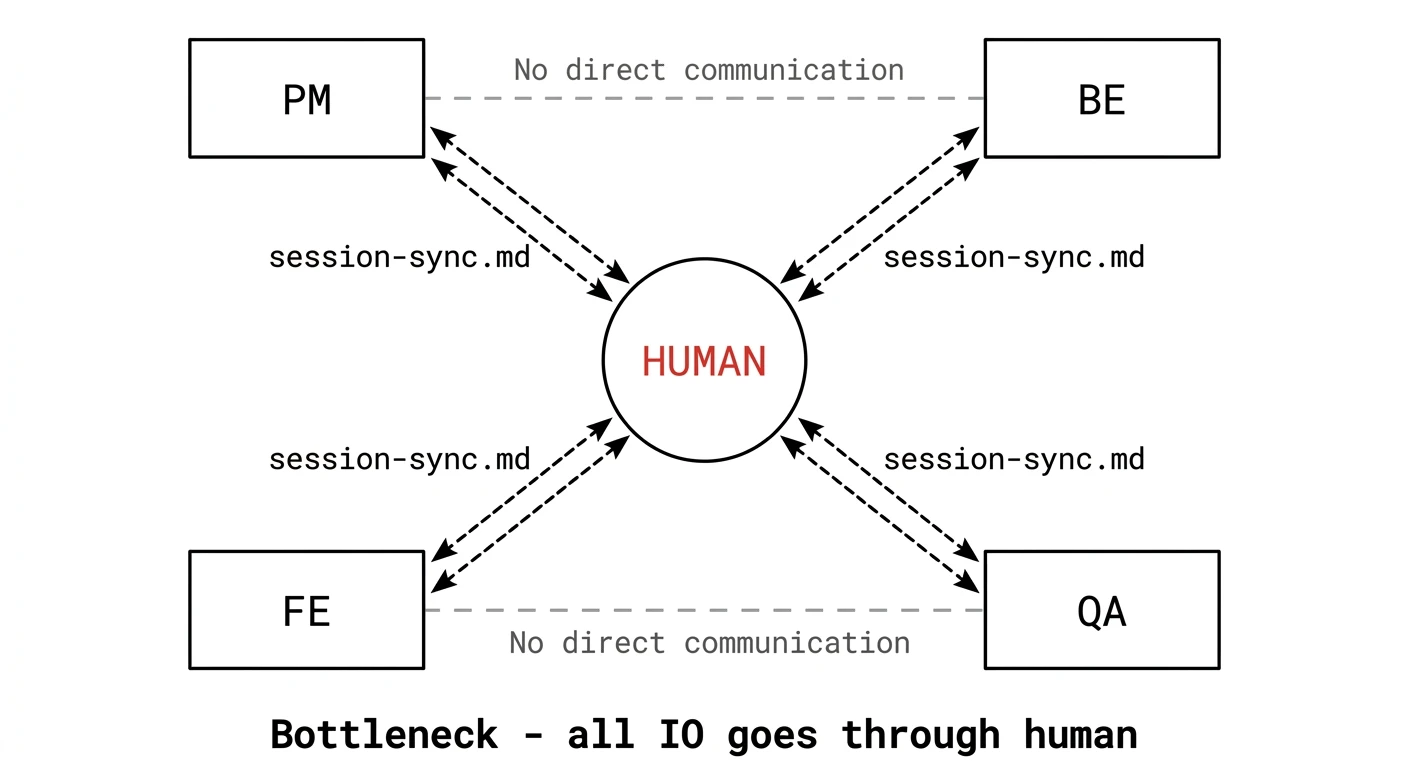
이 에피소드가 보여주는 건 결국 하나다. 모든 통신이 사람을 경유한다는 것. 에이전트끼리 직접 통신이 안 되니까, 매번 이런 루프를 탄다:
- PM 터미널 — PM 에이전트에게 작업 정의 → sync 문서에 지시 작성 트리거
- BE 터미널 — “sync 읽어” → BE 에이전트 작업 → sync 문서에 결과 작성 트리거
- PM 터미널 — PM 에이전트가 결과 확인 → FE용 지시 작성 트리거
- FE 터미널 — “sync 읽어” → 반복
인터셉트라는 장점은 확실하다. 하지만 세션이 늘어날수록 내가 각 터미널을 오가면서 트리거하는 횟수도 늘어난다. 세션마다 컨텍스트 윈도우 압박도 따로 온다. 결국 에이전트 4명이 병렬로 돌아도, 중계하는 사람은 직렬이다.
AI가 4명이 아니라 40명이어도, 중계가 사람이면 처리량은 사람 한계에 묶인다.
3개월간 체감한 병목 패턴을 정리하면 이렇다:
- 컨텍스트 스위칭 비용: PM 터미널에서 BE 결과를 확인하고, FE 터미널로 넘기고, 다시 QA 터미널에서 검증을 트리거한다. 각 전환마다 “지금 어디까지 왔지?”를 머리에서 리로드해야 한다. 세션 4개면 스위칭이 최소 3~4회/사이클.
- 대기 시간: BE가 작업하는 10분 동안 FE에게 다른 작업을 시킬 수 있다. 하지만 그러려면 내가 FE 터미널에서 새 작업을 정의해줘야 한다. 그 사이에 QA가 이전 빌드 검수를 끝내고 기다리고 있다. 결국 병렬이라고 해놓고 사람의 주의력은 직렬이다.
- 정보 손실: 앞서 본 optional 필드 사례처럼, 중계 과정에서 정보가 변형되거나 누락된다. 에이전트가 작성한 보고서의 정보 밀도는 높다. 그걸 다른 에이전트에게 전달할 때, 사람이 “이건 중요하겠지, 이건 안 중요하겠지” 판단하면서 필터링이 들어간다.
🔍 단서: 프로젝트가 작고 세션이 2개면 이 구조도 충분하다. 문제는 세션이 3개를 넘고, 변경 명세가 쌓이기 시작하면서부터다. 복잡도가 선형이 아니라 조합적으로 증가한다 — 세션 N개면 통신 경로는 N(N-1)/2개다.
📋 정리 — 수동 오케스트레이션 3개월 회고
| 항목 | 결과 | 비고 |
|---|---|---|
| 변경 명세서 | 66개 | PM→BE→FE→QA 파이프라인 |
| 평균 사이클 타임 | 40~60분 | 단일 기능 기준, 중계 대기 포함 |
| 정보 누락 사고 | 3건 | 모두 중계 과정에서 발생 |
| 빌드 실패율 | ~15% | 타입 불일치가 주 원인 |
| 측면 | 장점 | 한계 |
|---|---|---|
| 인터셉트 | ✅ 매 단계 검수 가능 | ❌ 사람이 놓치면 그대로 통과 |
| 병렬 처리 | ✅ 세션은 동시 실행 가능 | ❌ 중계는 직렬, 실질 병렬 아님 |
| 정보 전달 | ✅ 에이전트 보고서 품질 높음 | ❌ 중계 시 필터링/누락 발생 |
| 확장성 | ✅ 세션 추가 자유 | ❌ 사람 처리량이 병목 |
| 컨텍스트 | ✅ CLAUDE.md로 일관성 유지 | ❌ 세션별 윈도우 독립 → 중복 설명 |
수동 오케스트레이션이 나쁜 방법인 건 아니다. 에이전트를 믿을 수 있는지 검증하는 단계로서는 오히려 최적이었다. 3개월 동안 “잘게 쪼개면 에이전트가 정확하다”는 확신을 얻었고, session-sync 포맷은 나중에 자동화 프로토콜의 기반이 됐다.
다만, 확신이 생긴 다음에도 사람이 중계자에 남아 있을 이유는 없었다.
다음 편: 중계를 AI로 바꾸면?
이 구조로 작업하던 중에, Claude Code에 실험 기능으로 **Agent Teams**가 추가됐다. 리드 세션이 팀메이트를 spawn하고, 메시지 시스템으로 직접 통신하는 구조. session-sync.md를 사람이 트리거하는 대신, 시스템이 알아서 라우팅한다.
바로 써보고 싶었지만, WSL 환경에서 tmux 셋업 변경이 필요했고 — 진행 중인 프로젝트에 바로 적용하기엔 리스크가 있었다. 새로운 프로젝트에서 먼저 검증하고, 확인이 되면 이 프로젝트에도 적용하기로 했다.
다음 편에서는 그 첫 실전 투입 이야기다. 사내 ERP 시스템의 권한 체계가 seq 하드코딩으로 얼기설기 엮여 있었는데 — 팀 에이전트로 프론트/백엔드를 동시에 돌리면서 하루 만에 DB 기반 역할 시스템으로 리팩토링했다.
💡 후일담: 현재 이 프로젝트에도 팀 에이전트를 적용하여 운용 중이다.
📚 Claude Code 팀 에이전트 실전기 시리즈 (3편)
- 1. AI 4명을 부렸는데 결국 나만 바빴다 — 수동 오케스트레이션의 한계
- 2. Claude 팀 에이전트 첫 실전 — ERP 권한 체계를 하루 만에 뜯어고치다
- 3. Claude 팀 에이전트 완전 가이드 — 개념부터 실전 셋업까지